Überblick Link to heading
Im aktuellen Update des Corpus der Entscheidungen des Bundesverfassungsgerichts (CE-BVerfG) gibt es eine ganz besondere Neuerung!
Der Datensatz enthält nun eine spezialisierte Variante, die Zitate des Bundesverfassungsgerichts (BVerfG) zu seiner eigenen Rechtsprechung aus den Entscheidungstexten extrahiert und in strukturierter Form aufbereitet. Das Zitationsnetzwerk enthält im Update 2024-07-24 insgesamt ca. 163.000 Zitate zwischen ca. 14.000 Entscheidungen des BVerfG.
Das zweistufe Extraktions-Verfahren orientiert sich an Coupette, Juristische Netzwerkforschung (Mohr Siebeck 2019), S. 241–244, benutzt aber andere reguläre Ausdrücke, um die Erkennung von langen Blöcken mit Rechtsprechungszitaten zu verbessern.
Diese Variante ist noch in der Beta-Testphase! Folgende Rechtsprechungszitate sind bisher enthalten:
- Zitate innerhalb der amtlichen Sammlung (inklusive langer Blockzitate)
- Zitate von amtlicher Sammlung zu Aktenzeichen
- Zitate von Aktenzeichen zu Aktenzeichen
Zitate unter Angabe des Aktenzeichens sind weniger genau als Zitate zu konkreten Entscheidungen (bei denen Datum und ggf. Kollisionsziffer nötig sind), sind aber eine gute Näherung. Zitate konkreter Entscheidungen unter Angabe des Datums sind für die Zukunft vorgesehen, erfordern aber noch einiges an zusätzlichem Entwicklungsaufwand.
Das Zitationsnetzwerk wird als GraphML-Datei angeboten und kann z.B. einfach in graphische Software wie Gephi importiert und ohne Programmierkenntnisse genutzt werden.
Formal handelt sich um einen gewichteten, gerichteten Graphen (Digraph). Die Anzahl der Knoten gibt die Anzahl der BVerfGE-Entscheidungen/Aktenzeichen mit eingehenden und/oder ausgehenden Zitaten an. Die Anzahl der Kanten gibt die Anzahl der BVerfGE-Entscheidungen/Aktenzeichen-Paare mit mindestens einem Zitat an. Die Gewichte der Kanten geben die Anzahl der Zitate zwischen Knoten an.
Visualisierung des BVerfGE-Zitationsnetzwerks Link to heading
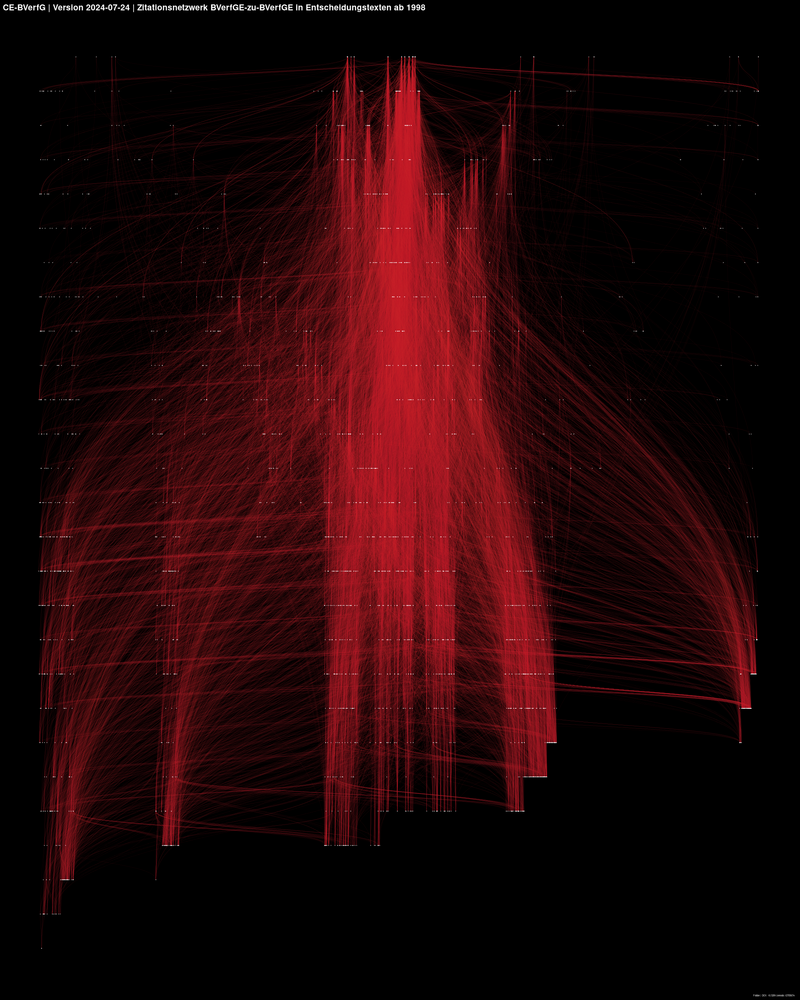
Das Diagramm visualisiert das Zitationsnetzwerk zwischen Entscheidungen der amtlichen Sammlung (BVerfGE) mit dem Sugiyama-Algorithmus, d.h. eine Teilmenge der veröffentlichten Netzwerkdaten.
Die weißen Punkte sind einzelne Entscheidungen, die roten Verbindungslinien sind Zitate. Mehrfachzitate zwischen Entscheidungspaaren sind hier nicht visualisiert, die Gewichte sind aber in den Netzwerkdaten enthalten.
Dieses Netzwerk ist streng hierarchisch, weil jüngere Entscheidungen der BVerfGE immer nur ältere Entscheidungen zitieren können, nicht umgekehrt. Man liest das Digramm daher von oben nach unten.
Man könnte wegen der starken Verbindungen zwischen manchen Entscheidungsclustern auch sagen, dass sich damit “Linien der Rechtsprechung” des BVerfG aufdecken lassen. Die Forschung dazu steht aber noch am Anfang.

Methodik Amtliche Sammlung (BVerfGE) Link to heading
Die Zitate zur BVerfGE werden aus dem Volltext in einem Zwei-Stufen-Verfahren extrahiert, ähnlich wie in Coupette, Juristische Netzwerkforschung (Mohr Siebeck 2019), S. 241–244.
Erste Stufe Link to heading
In der ersten Stufe werden die Zitierblöcke lokalisiert und aus dem Volltext gesammelt. Es wird die starke Annahme getroffen, dass Zitierblöcke mit “BVerfGE” (ignoriert Groß- und Kleinschreibung) eingeleitet werden und nur Whitespace, Zahlen, gewisse Sonderzeichen und gewisse Buchstaben enthalten. Zitierblöcke enden in der Regel mit einer runden Klammer, die in der REGEX nicht enthalten ist, um sie als Grenzzeichen zu nutzen.
Die konkrete genutzte Regular Expression (REGEX) ist die folgende:
1"BVerfGE[\\s\\d\\[\\];,\\.<>Rnfu-]+"
Ein gefundener Zitierblock sieht beispielsweise so aus:
BVerfGE 84, 133 <146 f.>; 85, 360 <372 f.>; 92, 140 <150> BVerfGE 89, 214 <232> BVerfGE 81, 242 <255>; 89, 214 <232 ff.> BVerfGE 81, 242 <254> BVerfGE 7, 198 <204 ff.> BVerfGE 84, 133 <154 ff.>; BVerfGE 89, 276 <289 f.> BVerfGE 88, 87 <96 f.> BVerfGE 82, 126 <146> BVerfGE 11, 245 <254>; BVerfGE 89, 15 <24> BVerfGE 5, 85 <198>; 59, 231 <263> BVerfGE 85, 337 <345>
Zweite Stufe Link to heading
In der zweiten Stufe werden aus allen Zitierblöcken die einzelnen Zitate extrahiert, standardisiert und mit der Ausgangsentscheidung verbunden. Die Extraktion trifft die starke Annahme, dass eine Entscheidung der amtlichen Sammlung entweder mit “BVerfGE” oder — bei einem Mehrfachzitat in einem Zitierblock — mit einem Semikolon eingeleitet wird.
Folgende REGEX kommt dabei zum Einsatz:
1regex.bverfge.cite <- paste0("(BVerfGE|;)\\s*", # hooks
2 "\\d{1,3},\\s*", # Volume
3 "\\d{1,3}") # Page
4
5print(regex.bverfge.cite)
1## [1] "(BVerfGE|;)\\s*\\d{1,3},\\s*\\d{1,3}"
Damit findet man zwei Varianten von Einzelzitaten:
- “BVerfGE 5, 85”
- “; 59, 231”
Die Einzelzitate werden anschließend bereinigt und standardisiert. Zum Ende hin werden Selbstzitate entfernt und Metadaten hinzugefügt.
Grenzen Link to heading
Die Extraktion mit regulären Ausdrücken hat Grenzen. Insbesondere folgende Probleme führen zur Nichterkennung von Zitaten:
- Tippfehler (außer Groß- und Kleinschreibung)
- Unregelmäßge Zitierweise
- Verkürzte Schreibweise wie in BVerfGE 60, 162: “BVerfGE 3, 19 (27), 383 (394); 4, 375 (381 f.);” — das Beispiel stammt von Coupette (2019: 246)
- Einfügung von Entscheidungsnamen wie in BVerfGE 42, 143: “BVerfGE 7, 198 (205ff) - Lüth -; 18, 85 (92f); 30, 173 (187f, 196f) - Mephisto -; 32, 311 (316)” — das Beispiel stammt ebenfalls von Coupette (2019: 246)
Coupette (2019) nutzt in der ersten Stufe eine REGEX, die strenger ist und die konkrete Form des Zitats (3 Zahlen gefolgt von einem Komma und weiteren 3 Zahlen) berücksichtigt. In der zweiten Stufe entfernt Coupette (2019) erst Inhalte in spitzen Klammern und extrahiert dann die Einzelzitate. Meine Vorgehensweise ist in der ersten Stufe liberaler, in der zweiten Stufe strenger.
Aktuell ist unklar, welche Strategie insgesamt besser ist, da die Prüfung auf falsch-negative und falsch-positive Fehler bei Coupette (2019: 245) nur N=33 Entscheidungen per Hand umfasste und ich falsch-positive und falsch-negative Fehler bisher nur informell mit kleinen Stichproben und Sichtkontrollen geprüft habe.
Methodik Aktenzeichen Link to heading
Über Coupette (2019) hinaus enthält dieser Datensatz auch zitierte Aktenzeichen (Aktenzeichen-zu-Aktenzeichen-Zitate) und Zitate von nicht-BVerfGE-Aktenzeichen zu BVerfGE-Entscheidungen (Aktenzeichen-zu-BVerfGE-Zitate).
Aktenzeichen sind einfacher zu erfassen und werden mit folgender REGEX gesucht:
1regex.az <- paste0("[12]\\s*", # Senatsnummer
2 "(AR|Bv[A-Z]|PBv[SUV]|PKH|Vz)", # Registerzeichen
3 "\\s*\\d{1,4}/", # Eingangsnummer
4 "\\d{2}") # Jahr
5print(regex.az)
1## [1] "[12]\\s*(AR|Bv[A-Z]|PBv[SUV]|PKH|Vz)\\s*\\d{1,4}/\\d{2}"
Um konkrete Entscheidungen zu zitieren müsste zusätzlich zum Aktenzeichen noch das Datum berücksichtigt werden. Weil dies die REGEX deutlich komplizierter macht, ist dieser Schritt noch in Arbeit. Im Datensatz sind allerdings 91.95 % aller ausgehenden Aktenzeichen einzigartig (unabhängig vom Datum), sodaß das Aktenzeichen eine gute Näherung darstellt.