- [Open Access] Zitationsnetzwerk des Bundesfinanzhofs als GraphML (2010-2024)
- [Open Access] Corpus der Entscheidungen des Bundesfinanzhofs (CE-BFH)
- [Open Access] Codebook zum CE-BFH Datensatz
Überblick Link to heading
Nach der Veröffentlichung von Zitationsdaten für das Bundesverfassungsgericht (BVerfG) und den Bundesgerichtshof (BGH) ist nun auch das Zitationsnetzwerk des Bundesfinanzhofs (BFH) online!
Das Corpus der Entscheidungen des Bundesfinanzhofs (CE-BFH) enthält nun eine spezialisierte Variante, welche Zitate des BFH zu seiner eigenen Rechtsprechung aus den Entscheidungstexten extrahiert und in strukturierter Form aufbereitet. Diese Variante ist noch in der Beta-Testphase.
Das Zitationsnetzwerk umfasst in Version 2025-01-14 insgesamt:
- ca. 180.000 Einzelzitate
- ca. 143.000 Kanten (gewichtete Zitierverbindungen)
- ca. 40.000 Knoten (BFH-Aktenzeichen und BFHE-Entscheidungen)
Folgende Zitate von Rechtsprechung zu Rechtsprechung sind enthalten:
- Zitate von Aktenzeichen zu Aktenzeichen
- Zitate von Aktenzeichen zu BFHE
Zitate unter Angabe des Aktenzeichens sind weniger genau als Zitate zu konkreten Entscheidungen (bei denen Datum und ggf. Kollisionsziffer nötig sind). Im Datensatz sind allerdings 98,73 % aller ausgehenden Aktenzeichen einzigartig (unabhängig vom Datum), sodass das Aktenzeichen in der Rechtsprechung des BFH eine fast perfekte Näherung darstellt. Die Auflösung der Zitate auf Entscheidungsebene ist geplant.
Eingehende BFHE-Zitate können exakt einer eingehenden Entscheidung zugeordnet werden. Die Quell-Dokumente sind jedoch nur mit dem Aktenzeichen hinterlegt, um eine Konkordanz mit dem Rest des Datensatzes herzustellen. Die Auflösung von Quell-Dokumenten nach BFHE ist mir derzeit leider nicht möglich, da ich aktuell (noch) keine Entsprechungstabelle zwischen amtlichen Sammlungen und Aktenzeichen/Datum-Zitaten habe.
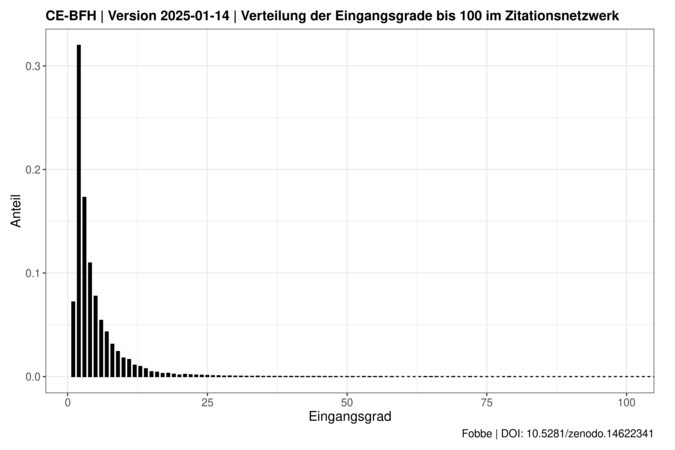
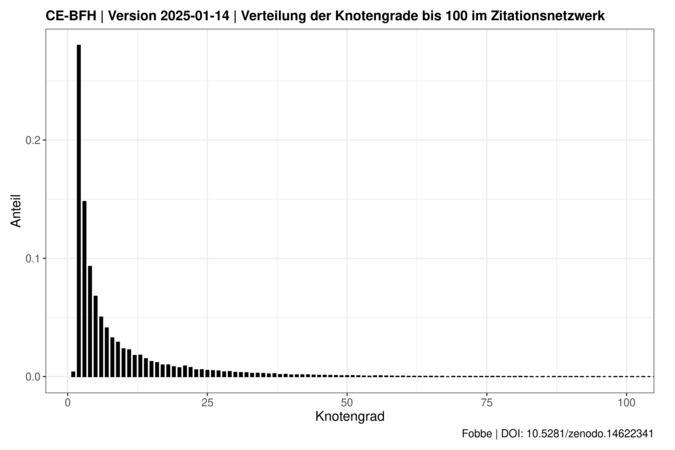
Verteilung der Eingangsgrade und Knotengrade Link to heading
Die folgenden Diagramme zeigen die Verteilung des Eingangsgrads (In-Degree) und des Knotengrads (Degree) des Netzwerks bis zu einem Wert von 100 an und bieten so einen schnellen Überblick über die Zitationshäufigkeiten innerhalb des Netzwerks.
Die Visualisierungen enden bei 100, weil es in der Regel einige Ausreißer-Entscheidungen gibt die sehr hohe Grade aufweisen und die Anzeige stark nach rechts verzerren. Diese können aber in der Regel einzeln tabellarisch gelistet werden, falls Interesse daran besteht.
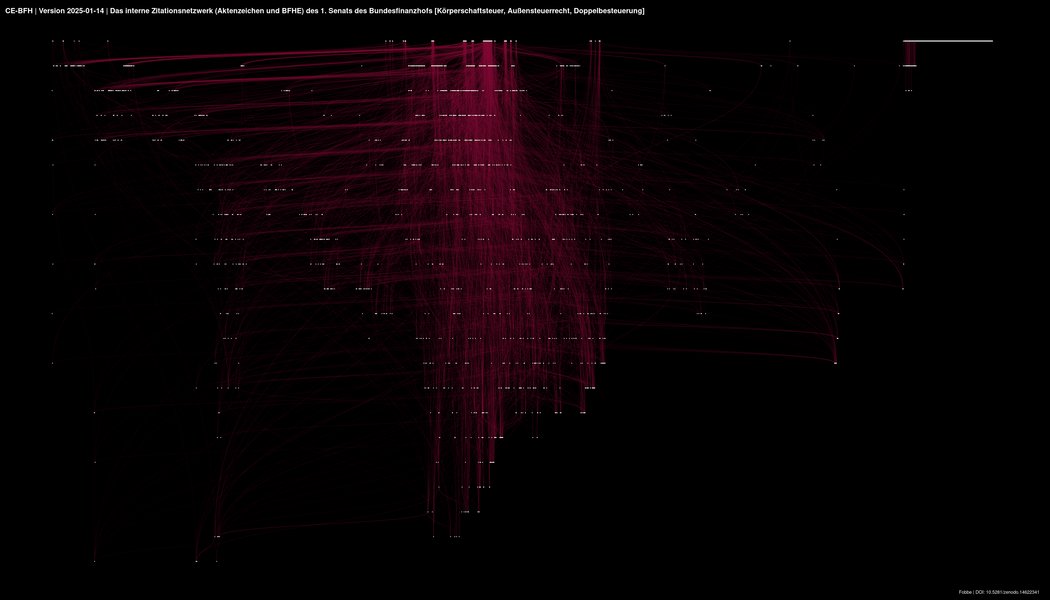
Visualisierung des Zitationsnetzwerks der ersten drei Senate des BFH Link to heading
Die unten gezeigten Diagramme visualisieren das Zitationsnetzwerk des ersten, zweiten und dritten Senats des Bundesfinanzhofs, d.h. eine Teilmenge der veröffentlichten Daten. Das gesamte Netzwerk ist in der Regel zu groß, um es in einem einzigen Diagramm unterzubringen.
Der zur Visualisierung verwendete Algorithmus ist Sugiyama.
Die weißen Punkte sind einzelne Aktenzeichen oder Entscheidungen der BFHE, die Verbindungslinien sind Zitate. Mehrfachzitate zwischen Entscheidungspaaren sind hier nicht visualisiert, die Gewichte sind aber in den Netzwerkdaten enthalten.
Dieses Netzwerk ist streng hierarchisch, weil jüngere Entscheidungen immer nur ältere Entscheidungen zitieren können, nicht umgekehrt. Man liest das Digramm daher von oben nach unten.
Man könnte wegen der starken Verbindungen zwischen manchen Entscheidungsclustern auch sagen, dass sich damit “Linien der Rechtsprechung” aufdecken lassen. Die Forschung dazu steht aber noch am Anfang.
Zitationsnetzwerk des 1. Senats des BFH Link to heading
Der 1. Senat des BFH ist zuständig für Körperschaftsteuer, Außensteuerrecht und Doppelbesteuerung.
Zitationsnetzwerk des 2. Senats des BFH Link to heading
Der 2. Senat des BFH ist zuständig für Erbschaftsteuer, Grunderwerbsteuer und Grundsteuer

Zitationsnetzwerk des 3. Senats des BFH Link to heading
Der 3. Senat des BFH ist zuständig für Einzelgewerbetreibende, Kindergeld und Investitionszulagen.

Technische Hinweise Link to heading
Das Zitationsnetzwerk wird als GraphML-Datei angeboten und kann z.B. einfach in graphische Software wie Gephi importiert und ohne Programmierkenntnisse genutzt werden.
Formal handelt sich um einen gewichteten, gerichteten Graphen (Digraph). Die Anzahl der Knoten (Number of Nodes) gibt die Anzahl der BFHE-Entscheidungen und Aktenzeichen mit eingehenden und/oder ausgehenden Zitaten an. Die Anzahl der Kanten (Number of Edges) gibt die Anzahl der Knoten-Paare mit mindestens einem Zitat an. Die Gewichte der Kanten geben die Anzahl der Zitate zwischen Knoten an. Die Ausgangsstärke (Strength (Out)) gibt die Summe aller einfachen Zitate an. Der Eingangsgrad (In-Degree) gibt die Anzahl der eingehenden Zitate pro Knoten an, d.h. ein grobes Maß der Wichtigkeit der Entscheidung.
| Number of Nodes | Number of Edges | Strength (Out) | Mean In-Degree | Max In-Degree | Min In-Degree |
|---|---|---|---|---|---|
| 39,875.00 | 143,281.00 | 178,806.00 | 3.54 | 120.00 | 0.00 |
- Das gesamte Netzwerk ist sehr groß und die Analyse ist daher ohne weitere Einschränkungen rechenintensiv und anspruchsvoll. In der Regel sollten Sie das Netzwerk auf die für Sie interessanten Teile reduzieren.
- Zur Reduktion des Netzwerks auf eine handliche Größe stelle ich v.a. zwei Variablen bereit: den Senat und das Registerzeichen.
- Die Extraktion mit regular expressions ist nicht perfekt. Es kann daher sein, dass Zitate fehlen, wenn sie nicht als solche erkannt wurden, wegen Tippfehlern, ungewöhnlichem Textumfeld etc. Es ist aktuell unklar wieviele Zitate fehlen könnten, weil es keinen Goldstandard zum Abgleich gibt. Wenn Ihnen größere Fehlbestände auffallen, melden Sie sich bitte.
- Sie können über die Variable “bfh-alternative” alle BFHE-Zitate auswählen (TRUE) oder nur Aktenzeichen-Zitate betrachten (FALSE)
Metadaten Link to heading
Die Knoten des Netzwerks sind mit Metadaten aus dem Hauptdatensatz angereichert. Deshalb sind grundsätzlich nur im Hauptdatensatz vorhandene Aktenzeichen (d.h. solche die in der BFH-Datenbank veröffentlicht sind) mit allen Metadaten verbunden.
Für alle anderen Zitate konnte ich nur solche Metadaten hinterlegen, die aus dem Aktenzeichen (Registerzeichen, Senatsnummer) oder dem BFH-Zitat (BFH ja/nein, Nummer des Bandes) mit REGEX zu extrahieren waren.
Hinweis: die Variable “bfhe” gibt an, ob die das Aktenzeichen in der BFH-Datenbank als V- oder NV-Entscheidung markiert ist. Die Variable “bfhe-alternative” dagegen ist TRUE/FALSE und gibt an, ob das Zitat (d.h. der Name des Knotens) die Zeichenkette “BFHE” enthält.
Methodik Aktenzeichen Link to heading
Dieser Datensatz enthält sowohl zitierte Aktenzeichen (Aktenzeichen-zu-Aktenzeichen-Zitate), als auch Zitate von Aktenzeichen zu BFHE-Zitate (Aktenzeichen-zu-Sammlung-Zitate).
Aktenzeichen sind verhältnismäßig einfach zu erfassen. Die Funktion f.citation_network.R erstellt erstellt eine komplexe REGEX, die jeweils die relevanten Registerzeichen in die Suche aufnimmt. Der Source Code ist zu komplex um ihn hier im Detail zu besprechen, sehen Sie sich bei Interesse bitte die Funktion genauer an.
Um konkrete Entscheidungen zu zitieren müsste zusätzlich zum Aktenzeichen noch das Datum berücksichtigt werden. Weil dies die REGEX deutlich komplizierter macht, ist dieser Schritt noch in Arbeit. Im Hauptdatensatz sind allerdings 98,73 % aller ausgehenden Aktenzeichen einzigartig (unabhängig vom Datum), sodass das Aktenzeichen eine gute Näherung darstellt.
Methodik BFHE Link to heading
Die Zitate zu der amtlichen Sammlung BFHE werden aus dem Volltext in einem Zwei-Stufen-Verfahren extrahiert, ähnlich wie in Coupette, Juristische Netzwerkforschung (Mohr Siebeck 2019), S. 241–244.
Erste Stufe Link to heading
In der ersten Stufe werden die Zitierblöcke lokalisiert und aus dem Volltext gesammelt. Es wird die starke Annahme getroffen, dass Zitierblöcke mit “BFHE” (ignoriert Groß- und Kleinschreibung) eingeleitet werden und nur Whitespace, Zahlen, gewisse Sonderzeichen und gewisse Buchstaben enthalten.
Zitierblöcke enden in der Regel mit einer runden Klammer, die in der REGEX nicht enthalten ist, um sie als Grenzzeichen zu nutzen. Auch Gleichheitszeichen (=) sind nicht enthalten, damit die REGEX vor einem Hinweis auf einen alternative Abdruck abbricht.
Die konkreten regular expressions (REGEX) sind die folgenden:
1"BFHE[\\s\\d\\[\\];,\\.<>Rnfu-]+"
Zweite Stufe Link to heading
In der zweiten Stufe werden aus allen Zitierblöcken die einzelnen Zitate extrahiert, standardisiert und mit der Ausgangsentscheidung verbunden. Die Extraktion trifft die starke Annahme, dass eine Entscheidung der amtlichen Sammlungen entweder mit “BFHE” oder bei einem Mehrfachzitat in einem Zitierblock mit einem Semikolon eingeleitet wird. Folgende REGEX kommen dabei zum Einsatz:
1regex.cite <- paste0("(BFHE|;)\\s*", # hooks
2 "\\d{1,3},\\s*", # Volume
3 "\\d{1,3}") # Page
4
5print(regex.cite)
1## [1] "(BFHE|;)\\s*\\d{1,3},\\s*\\d{1,3}"
Damit findet man zwei Varianten von Einzelzitaten:
- “BFHE 248, 287”
- “; 248, 287”
Die Einzelzitate werden anschließend bereinigt und standardisiert. Zum Ende hin werden Selbstzitate entfernt und Metadaten hinzugefügt.
Grenzen Link to heading
Die Extraktion mit regulären Ausdrücken hat Grenzen. Insbesondere folgende Probleme führen zur Nichterkennung von Zitaten:
- Tippfehler (außer Groß- und Kleinschreibung)
- Unregelmäßge Zitierweise
- Verkürzte Schreibweise wie in BVerfGE 60, 162: “BVerfGE 3, 19 (27), 383 (394); 4, 375 (381 f.);” — das Beispiel stammt von Coupette (2019: 246)
- Einfügung von Entscheidungsnamen wie in BVerfGE 42, 143: “BVerfGE 7, 198 (205ff) - Lüth -; 18, 85 (92f); 30, 173 (187f, 196f) - Mephisto -; 32, 311 (316)” — das Beispiel stammt ebenfalls von Coupette (2019: 246)
Mehr zu juristische Zitationsnetzwerken Link to heading
Interesse an weiteren Zitationsdaten für deutsche Bundesgerichte? Für folgende Gerichte habe ich Zitationsnetzwerke mit einer vergleichbaren Methodik veröffentlicht:
- Zitationsnetzwerk des Bundesverfassungsgerichts (BVerfG)
- Zitationsnetzwerk des Bundesgerichtshofs (BGH)
Die Arbeit von Professor Dr. Dr. Corinna Coupette ist zudem immer einen Blick wert und steht an der Spitze der aktuellen Forschung zu juristischen Netzwerken (v.a. mit Bezug zu Deutschland).