Repräsentativität, Stichprobe und Grundgesamtheit
Überblick Link to heading
Die Repräsentativität von Meinungsumfragen und wissenschaftlichen Untersuchungen ist eines der großen methodischen Themen unserer Zeit. Die Verallgemeinerbarkeit von Forschungsergebnissen hängt maßgeblich von der Qualität und Quantität der untersuchten Daten ab. Zentral für diese externe Validität sind die Konzepte von Stichprobe, Grundgesamtheit und Repräsentativität.
Korrekt gezogene Zufallsstichproben mit einer vernünftigen Größe lassen den Schluss von wenigen hundert bis tausend Personen auf ein ganzes Land zu. Im Gegenzug sind schlecht gezogene Stichproben oft auf unbekannte und unreparierbare Art verzerrt.
Wenn wichtige Entscheidungen auf schlechten Daten beruhen, können große und weitreichende Schäden entstehen. Es ist für Jurist:innen daher zentral zu wissen, ob und wie sich Ergebnisse verallgemeinern lassen.
In diesem Tutorial geht es um die folgenden Themen:
- Was sind beschreibende Statistik und schließende Statistik?
- Was sind Stichprobe und Grundgesamtheit?
- Wie das Referenzklassenproblem der Münchener Sicherheitskonferenz zum Verhängnis wurde
- Die Lösung des Referenzklassenproblems durch Zufallsstichproben und statistische Korrekturen
- Der Niedergang des Literary Digest durch eine verzerrte Stichprobe
- Die verhängnisvolle Umfragepraxis der Bundesrechtsanwaltskammer (BRAK)
- Visuelle Intuition für Zufallsstichproben
- Numerische Intuition für Zufallsstichproben
- Das Bootstrap-Verfahren für die Schätzung der Genauigkeit verschiedener Stichprobengrößen
Das Tutorial ist für den Anfang etwas theorielastig, enthält aber in der zweiten Hälfte viel interessanten R Code zum nachprüfen und mitmachen. Insbesondere die visuellen Darstellungen sind auf dem eigenen Computer noch einmal viel eindrucksvoller, als wenn man sie nur vorbereitet mitnimmt.
Benutzen Sie für dieses Tutorial am besten WebR.
WebR ist eine Web-Anwendung, die direkt in ihrem Browser läuft und den R Code lokal auf ihrem eigenen Computer ausführt, nicht in der Cloud. Eine Installation ist nicht notwendig.
Selbstverständlich können Sie den Code aus dem Tutorial auch lokal mit einer typischen Entwicklungsumgebung wie RStudio oder in der Cloud mit Posit Cloud ausführen.
Inhaltsverzeichnis Link to heading
Grundgesamtheit und Stichprobe Link to heading
Statistische Methoden lassen sich grundsätzlich in zwei große Bereiche einordnen:
- Beschreibende Statistik (deskriptive Statistik)
- Schließende Statistik (Inferenzstatistik)
Mit der beschreibenden Statistik (deskriptive Statistik) werden Daten durch Analyse und Reduktion so aufbereitet, dass aus einer großen Datenmasse eine für Menschen interpretierbare und nützliche Zusammenfassung entsteht. Klassische Methoden der beschreibenden Statistik sind Verteilungen und Lageparameter wie Histogramme oder das arithmetische Mittel.
Die schließende Statistik (Inferenzstatistik) widmet sich dem zentralen praktischen Problem der Natur- und Sozialwissenschaften: wie können wir allgemeine Erkenntnisse über die Welt und ihre Bewohner:innen erlangen, wenn es unmöglich oder unverhältnismäßig teuer ist, Daten zu einer Forschungsfrage vollständig zu erheben? Die Grundlagen der schließenden Statistik sind das Thema dieses Tutorials.
Die Statistik entwickelte sich als eigenständige Disziplin aus dem Wunsch heraus, effektiver Agrarwissenschaft betreiben zu können. Viele Pioniere der Statistik wollten mit möglichst wenig Resourcenaufwand möglichst viele landwirtschaftliche Methoden (Dünger, Züchtung usw.) möglichst effizient testen, um herauszufinden welche von ihnen den Ertrag der untersuchten Nutzpflanzen am besten steigern. Die Inferenzstatistik hat hierzu einen bedeutenden Beitrag geleistet.
Ronald Aylmer Fisher, der Vater der modernen Statistik, verbrachte den vielleicht produktivsten Abschnitt seiner Laufbahn an der Rothamsted Experimental Station und machte sich in dieser Zeit einen Namen mit der Analyse von Daten zu Experimenten an Nutzpflanzen. William Sealy Gosset (vor allem bekannt unter seinem Pseudonym “Student”) war im Hauptberuf Braumeister der Guinness-Brauerei in Irland und entwickelte den berühmten t-test (Student 1908) und andere statistische Verfahren um den Ertrag von Gerste zu steigern und besseres Bier brauen zu können. Die Statistik ist daher bis heute stark von ihrer Verbindung mit agrar- und biowissenschaftlichen Erkenntniszielen beeinflusst.
Der bekannteste Anwendungsfall der Inferenzstatistik in der Moderne ist aber die Meinungsumfrage. In einer Demokratie ist es von großer praktischer und demokratietheoretischer Bedeutung, die Meinung des Volkes auch zwischen großen Wahlen realistisch einschätzen and darauf reagieren zu können. Alle 80+ Millionen Bundesbürger:innen zu jeder Sachfrage einzeln zu befragen wäre jedoch unfassbar teuer und in kurzen Abständen kaum machbar. In Berlin tut man sich schon schwer damit die Bundestagswahl allein in der Hauptstadt verfassungsrechtlich sauber zu organisieren.1
Wie ist es also möglich, eine realistisch erreichbare Anzahl Personen zu befragen, dennoch aber eine saubere Einschätzung der Meinung der gesamten Bevölkerung zu erhalten?
Zur Lösung dieses Problems sind in der Inferenzstatistik zwei Konzepte grundlegend:
- Grundgesamtheit — die Menge aller für die Forschungsfrage relevanten Einheiten. Das können Bundesbürger:innen sein, Kaulquappen, Produkte einer Fabrik oder aber auch archäologische Stätten.2
- Stichprobe — eine Teilmenge der anvisierten Grundgesamtheit. Die Auswahl einer Stichprobe kann auf viele Arten geschehen, nicht alle davon sind hilfreich.
Eine vollständige Untersuchung von Grundgesamtheiten ist meist zu teuer, unethisch (z.B. Medikamentenstudien) oder schlicht unmöglich (nicht alle Mitglieder der Grundgesamtheit sind bekannt). Eine Ausnahme sind beispielsweise manche Fragen in der Friedensforschung, denn man kennt zumindest für die Zeit ab 1945 fast alle Kriege und wichtigen politischen Ereignisse.3
Aufgabe der Inferenzstatistik ist die Herstellung einer Zusammenhangs zwischen Stichprobe und Grundgesamtheit. Eine gute Stichprobe lässt — mit einer gewissen Unsicherheit — eine Hochrechnung auf die Grundgesamtheit zu.
Das Referenzklassenproblem Link to heading
Der Schluss von einer Stichprobe auf die Grundgesamtheit ist grundsätzlich nur dann möglich, wenn die Stichprobe gut gezogen wurde. Wir lesen daher oft in den Nachrichten, dass eine Stichprobe “repräsentativ” wäre, insbesondere wenn Journalist:innen nur unkritisch Pressemitteilungen abschreiben (LTO 2020). Aber was ist Repräsentivität?
Allgemein gesprochen ist eine Stichprobe dann repräsentativ, wenn sie in allen relevanten Merkmalen der Grundgesamtheit möglichst nahe kommt. Wir kennen viele Fälle aus dem Alltag bei denen uns ein Störgefühl überkommt, wenn das nicht der Fall ist.
Ein Beispiel: wir wissen, dass das Verhältnis von Männern und Frauen in der Gesellschaft (Grundgesamtheit) etwa 50% zu 50% ist.4 Wenn auf dem Foto eines CEO-Lunches auf der Münchener Sicherheitskonferenz 2022 100% Männer und 0% Frauen zu sehen sind, ist uns sofort klar, dass das keine repräsentative Stichprobe der Gesellschaft sein kann.
Aber wie können wir wissen, welche Merkmale für unsere Fragestellung relevant sind? Angenommen wir befragen eine Stichprobe der Bevölkerung, welche Partei sie bei der nächsten Bundestagswahl wählen würden. Wie bekommen wir das richtige Verhältnis aus Modelleisenbahnbauer:innen, Künstler:innen, Marathonläufer:innen und Töpfer:innen hin? Oder sind diese Kriterien für diese Forschungsfrage gar nicht relevant?
Das ist das Referenzklassenproblem.
Das Referenzklassenproblem besagt vereinfacht, dass man die Welt, Menschen und Ereignisse in unendlich viele Schubladen einteilen kann.
Menschen können gleichzeitig Anwält:in, Programmierer:in, Elternteil, Pilzsammler:in, jung, krank, sportlich aktiv, Parteimitglied, Führungskraft, Untergebener:in, Ausländer:in, Staatsbürger:in und vieles mehr sein.
Die korrekte Auswahl relevanter Merkmale/Eigenschaften/Referenzklassen aus dieser Vielzahl ist der wesentliche Herausforderung des Referenzklassenproblems. Meistens ist die Menge aller relevanten Faktoren unbekannt und nicht gezielt bestimmbar.
Verwandte Probleme aus der Menschenrechtspraxis sind Mehrfachdiskriminierung und Intersektionalität. In Diskriminierungsfällen können viele Faktoren gleichzeitig relevant sein (Mehrfachdiskriminierung) oder sich sogar zu einer ganz eigenen Diskriminierungserfahrung verbinden (Intersektionalität). Welche Eigenschaften einer Person für eine Diskriminierung relevant sind kann je nach Ort, Zeit und sozialem Kontext völlig unterschiedlich sein.
Zufall und Statistische Korrekturen als Lösung? Link to heading
Für das Referenzklassenproblem und die Herstellung repräsentativer Ergebnisse gibt es vor allem zwei Lösungsansätze:
- Zufällige Auswahl der Einheiten (Zufallsstichprobe)
- Gewichtung, Quotierung oder statistische Kontrolle von Merkmalen
Die Zufallsstichprobe ist die eleganteste Methode, um dem Referenzklassenproblem zu begegnen. Wenn alle Einheiten der Stichprobe zufällig aus der Grundgesamtheit ausgewählt werden, werden alle Merkmale durchmischt und jede Einheit und jedes Merkmal hat die gleiche Chance in der Stichprobe zu landen. Deshalb werden sie oft auch mit “iid” abgekürzt (independent and identically distributed). Zufallsstichproben sind der Idealfall der Repräsentativität.
In Industrieländern wird bei Meinungsumfragen oft eine zufällige Auswahl von Telefonbesitzer:innen angerufen. In anderen Fällen findet eine Clusterbildung (z.b. Zufallsauswahl von Häuserblöcken, dann zufällige Befragung von Haushalten) oder Stratifizierung (Zufallsauswahl aus nach Merkmalen beschränkten Teilen der Grundgesamtheit) statt, um die Ziehung zu vereinfachen.
Echte Zufallsstichproben sind in der Praxis schwierig zu ziehen, denn es besteht meist kein Zugang zu einer vollständigen Liste der Grundgesamtheit. In neuerer Zeit ist auch die Teilnahmequote an Umfragen deutlich gesunken. Gelman nennt bereits Antwortverweigerungen von knapp 90% bei nationalen Telefonumfragen in den USA (Gelman 2017).5
Selbst Zufallsstichproben haben aber einen Schätzfehler abhängig von ihrer Stichprobengröße — der nicht zu unterschätzen ist. Die Quantität der Stichprobe hat neben der Qualität eine eigenständige Bedeutung.
Die Gewichtung, Quotierung oder statistische Kontrolle von Merkmalen ist immer zweite Wahl, kann aber von Interesse sein, wenn keine echte Zufallsstichprobe möglich ist. So würden wir bei einer “repräsentativen” Auswahl von Gäst:innen für ein CEO-Lunch versuchen eine Frauenquote von ca. 50% zu erreichen, einen Migrationshintergrund von ca. 30% usw. Das kann gelegentlich seltsame Blüten treiben, ist aber in vielen Fällen die einzig praktikable Möglichkeit.
Ernsthafte Probleme entstehen aber sobald nicht alle relevanten Merkmale bekannt sind, die Verteilung der Merkmale in der Grundgesamtheit unbekannt ist oder eine Messung schwierig ist. Alle diese Probleme sind leider der Regelfall, weshalb die Aussagekraft und Verallgemeinerbarkeit von Nicht-Zufallsstichproben begrenzt sind. In der Forschung wird nicht selten versucht diesem Problem mit komplexen statistischen Korrekturen zu begegnen. Statistische Korrekturen setzen aber erhebliches Vorwissen über die konkrete Forschungsfrage und die damit verbundenen Probleme voraus. Diese Korrekturen sind daher oft nicht möglich oder können irreführend, wenn nicht mit großer Sorgfalt durchgeführt.
In einer Studie stellten Wang et al. (2015) eine Befragung von Xbox-Spieler:innen vor, die trotz der außergewöhnlich großen aber unrepräsentativen Stichprobe (N = 345.858, aber 93% Männer) durch Einsatz von statistischen Korrekturen (Multi-Level Regression und Poststratifizierung) relativ gute Ergebnisse für die Vorhersage der US-Präsidentschaftswahl 2012 liefern konnten.6
Das soll aber nur ein Beispiel sein. Wir werden in diesem Tutorial nur die Technik von Zufallsstichproben behandeln.
Aufstieg und Niedergang des Literary Digest Link to heading
Wieso ist es so wichtig, wie eine Stichprobe gezogen wurde? Die Geschichte von Aufstieg und Niedergang des Literary Digest zeigt, wie verzerrte Stichproben nicht nur zu falschen Ergebnissen führen, sondern einen nationalen Ruf ruinieren und ein ganzes Nachrichtenmedium in den Ruin reißen können.
Der Literary Digest war ein US-amerikanisches Nachrichtenmagazin, herausgegeben von 1890 bis 1938. Ab 1916 führte das Magazin regelmäßig Umfragen im Vorfeld der US-Präsidentschaftswahlen durch und konnte bis 1936 immer den Wahlgewinner korrekt vorhersagen. Für die Wahl im Jahr 1936 zwischen Franklin D. Roosevelt und Alfred Landon verteilte das Magazin gar 10 Millionen (!) Fragebögen und erhielt 2,.27 Millionen (!) Antworten.
Auf Basis dieser Umfrage kürte der Literary Digest den Kandidaten Alfred Landon zum wahrscheinlichen Sieger der Präsidentschaftswahl (55% für Landon, 41% für Roosevelt) und lag damit ganz gravierend falsch. Tatsächlich gewann Roosevelt die Präsidentschaftswahl mit einer gewaltigen landslide victory: er erhielt 61% zu 37% im popular vote und gewann 46 der 48 Bundesstaaten.7 Der Rufschaden war so enorm, das der Literary Digest sich nie wieder erholte und 1938 für immer seine Türen schloss.
Was war passiert? Die Stichprobe war nicht repräsentativ, sondern verzerrt:
- Die Rücklaufquote betrug nur etwas über 20%
- Befragt wurden nur bestimmte Bevölkerungsgruppen (eigene Leserschaft, Automobilbesitzer, Telefonbesitzer)
Ein Problem auf das sich alle statistischen Kommentator:innen einigen können ist die Rücklaufquote: 2.27 Millionen Antworten auf 10 Millionen Fragebögen. Wenn die Ergebnisse einer Umfrage vor allem auf die Antworten von besonders motivierten Personen gründen und diese Motivation in einem speziellen Interesse gründet, dann ist eine Verzerrung fast vorprogrammiert. So scheinen bei der Literary Digest-Umfrage vor allem Anhänger von Landon und Gegner von Roosevelt geantwortet zu haben.
Ein anderes Problem war die Befragung von a) der eigenen Leserschaft, b) Automobilbesitzer:innen und c) Telefonbesitzer:innen. Alle diese Gruppen hatten ein überdurchschnittliches Einkommen und größere Sympathien für Landon.
George Gallup, Gründer der Gallup Organization, gelang es den Sieger der Präsidentschaftswahl mit einer repräsentativen Zufallsstichprobe von 50.000 Teilnehmer:innen korrekt vorherzusagen — der Beginn der modernen Umfrageforschung.
- BRYSON, Maurice C. The Literary Digest poll: Making of a statistical myth. The American Statistician, 1976, 30. Jg., Nr. 4, S. 184-185.
- SQUIRE, Peverill. Why the 1936 Literary Digest poll failed. Public Opinion Quarterly, 1988, 52. Jg., Nr. 1, S. 125-133.
- KAPLAN, Robert M.; CHAMBERS, David A.; GLASGOW, Russell E. Big data and large sample size: a cautionary note on the potential for bias. Clinical and translational science, 2014, 7. Jg., Nr. 4, S. 342-346.
Repräsentativität in der Praxis der Bundesrechtsanwaltskammer Link to heading
Trotz langjähriger Arbeit der Statistik und Meinungsforschung seit 1936 (!) haben es diese Erkenntnisse selten in die moderne juristische Forschung und Praxis geschafft. Insbesondere werden von Jurist:innen seit vielen Jahren nicht-repräsentative Umfragen als “repräsentativ” umdeklariert, um damit Politik zu machen. Kaum belastbare Ergebnisse werden zum repräsentativen Willen des Volkes bzw. bestimmter Berufsgruppen erklärt.
Um diese Kritik zu konkretisieren habe ich einige öffentliche Verlautbarungen der Bundesrechtsanwaltskammer (BRAK) ausgewählt. Achtung: die BRAK ist nicht die einzige Institution oder Person, die methodisch fragwürdige Umfragen benutzt, um Politik zu machen. Sie tut es aber besonders oft und mit Beharrlichkeit, weshalb ich die Beispiele von dort ausgesucht habe. Jedes der Beispiele lässt aus didaktischer Sicht gut an die Fehler des Literary Digest anschließen und zeigt konkrete Irrtümer auf, für die es konkrete Lösungen gibt.8
Beispiel 1: Kündigung von Anderkonten Link to heading
Anderkonten sind Konten, mit denen Rechtsanwält:innen treuhänderisch fremde Gelder verwalten, z.B. für Mandant:innen. Wegen strengerer Geldwäschevorschriften machte man sich 2022 Sorgen um die Kündigung von anwaltlichen Anderkonten durch Banken, weshalb die BRAK von ihren Mitgliedern wissen wollte, wie die Lage ist. In ihrer Presseerklärung Nr. 3/2022 schreibt die BRAK:
Ein Fünftel aller anwaltlichen Anderkonten gekündigt
Umfrage der BRAK deckt auf: knapp 21 Prozent aller Teilnehmerinnen und Teilnehmer erhielten Kündigung
Im Zeitraum vom 07.-13.02.2022 führte die Bundesrechtsanwaltskammer (BRAK) eine Umfrage durch, um zu eruieren, wie viele Kolleginnen und Kollegen konkret durch die bankseitigen Kündigungen von Sammelanderkonten betroffen sind. An der Umfrage der BRAK nahmen über 9.600 Rechtsanwältinnen und Rechtsanwälte teil, von denen über 8.100 die Umfrage vollständig, weitere rund 1.500 teilweise beantwortet haben.
Die Auswertung der Ergebnisse bestätigt die Befürchtung der BRAK, dass es sich um ein systemisches Problem großen Ausmaßes handelt. Knapp 21 Prozent der teilnehmenden Rechtsanwältinnen und Rechtsanwälte erhielten eine Kündigung für das Sammelanderkonto durch ihre Bank, 2,4 Prozent für ihre Einzelanderkonten. (…)
Rechtsanwältin Ulrike Paul, Vizepräsidentin der BRAK, zeigt sich über die Ergebnisse besorgt: “Unter Berücksichtigung der Teilnehmerzahl können wir die Umfrage als repräsentativ bezeichnen und davon ausgehen, dass bereits jetzt über ein Fünftel der deutschen Anwaltschaft persönlich betroffen ist. (…)”
Ist diese Umfrage wirklich repräsentativ? Die Berufung auf die Teilnehmer:innenzahl und die sonstige Umfragepraxis der BRAK lässt den Schluss zu, dass hier keine Zufallsauswahl der Teilnehmer:innen stattfand.9 Ohne eine Zufallsauswahl ist eine Verzerrung der Ergebnisse vorprogrammiert, denn man muss davon ausgehen, dass gerade solche Anwält:innen mit gekündigten Anderkonten an der Umfrage teilgenommen haben, um ihrerm Ärger Luft zu machen.
Rechnen wir noch etwas nach. Immerhin wurden die Detail-Ergebnisse der Umfrage veröffentlicht.
2022 waren nach Angaben der BRAK 165.587 Rechtsanwält:innen zugelassen. Das ergibt eine Rücklaufquote von:
1ruecklauf <- 9654 / 165587
2print(ruecklauf)
1## [1] 0.05830168
Eine Rücklaufquote von 5,83% ist noch deutlich schlechter als die ca. 20%, die der Literary Digest zu verzeichnen hatte. Mit anderen Worten, 94,17% der Rechtsanwält:innen nahmen an der Umfrage nicht teil.
Wenn wir jetzt noch Frage 2 mit den Sammelanderkonten betrachten, erhalten wir den realen Anteil der Betroffenen:
1betroffene <- (1836 + 210 ) / 165587
2print(betroffene)
1## [1] 0.01235604
Aufgrund dieser nicht-repräsentativen Umfrage können wir also nur davon ausgehen, dass ca. 1,24% der Anwaltschaft betroffen sind. Das ist weit von dem “Fünftel der deutschen Anwaltschaft” entfernt, wie von der BRAK behauptet.
Diese Pressemitteilung ist aber beispiehaft für einen verbreiteten Irrtum. Moderne Umfragen arbeiten mit einer Stichprobengröße von ca. 1000 Befragten, weshalb oft von der Zahl der Befragten auf die Repräsentativität geschlossen wird. Repräsentativität wird aber vor allem durch die Zufallsauswahl begründet. Die Zahl der Befragten ist bedeutsam für den Schätzfehler.
Die Teilnehmerzahl allein kann keine Repräsentativität begründen, es sei denn es wurde fast die gesamte Grundgesamtheit befragt. Das ist in dieser Umfrage nicht der Fall.
Was wäre eine ehrliche Interpretation? Beispielsweise das mindestens 1,24% der Anwaltschaft betroffen sind. Das ist gar nicht so wenig, belegt die Existenz des Problems und ein gewisses Gewicht.
Beispiel 2: Corona-Umfrage Link to heading
Während der Corona-Krise führte die BRAK mehrere Online-Umfragen durch, um sich ein Bild der Anwaltschaft zu machen. Hier soll es um die dritte Corona-Umfrage (2021) gehen. Auch für diese Umfrage sind die Ergebnisse im Detail veröffentlicht. Zusammenfassend schreibt die BRAK auf ihrer Webseite:
Die dritte Umfrage spiegelt einmal mehr die tatsächliche Situation in Deutschland bezüglich Verteilung nach Rechtsgebieten und Kanzleiorganisationsformen recht gut wieder. Die Umfrageergebnisse zeichnen aufgrund der Durchmischung der Teilnehmer (vom Einzelanwalt bis zum Partner in der Großkanzlei) ein repräsentatives Bild der aktuellen Situation der Anwaltschaft.
Hier wird durch die BRAK von der “Durchmischung” der Teilnehmer:innnen auf die Repräsentativität geschlossen. Auch das ist ein verbreiteter Fehler. Weder fand eine ex-ante Zufallsauswahl, noch eine ex-post statistische Korrektur mit Abgleich zu der Verteilung in der Grundgesamtheit statt.
Mal davon abgesehen ist es auch kurios, dass allein die Organisationsform im Spektrum von Einzelanwalt bis Großkanzlei relevantes Merkmal für die Diversität sein soll.
Wegen dem Referenzklassenproblem kann eine Vielzahl von Faktoren die Ergebnisse beeinflussen. Sinnvolle Repräsentativität kann nur erreicht werden durch:
- Zufallsauswahl der Teilnehmer:innen VOR Durchführung der Umfrage (bevorzugt)
- Statistische Korrektur NACH Durchführung der Umfrage auf Basis der Grundgesamtheit (schwierig)
- Befragung fast der gesamten Grundgesamtheit (Ausnahmefall)
Kann man hieraus Schlüsse auf die gesamte Anwältinnen:schaft ziehen? Nein. Man kann allenfalls Probleme herausarbeiten und bessere Folge-Umfragen entwerfen.
Zusammenfassung Link to heading
In diesen Fallstudien sieht man, wie allein aus der Teilnehmer:innenzahl oder aus den wenigen Teilnehmerattributen methodisch unsaubere Online-Umfragen nachträglich als “repräsentativ” erklärt werden. Bei der Durchführung von Umfragen gibt es aber noch viele, viele andere methodische Probleme, die wir hier nicht besprechen können. Wie kann man also in der Praxis besser vorgehen? Vier Möglichkeiten gäbe es:
- Mit Expert:innen zusammenarbeiten. Es gibt sowohl in der Wissenschaft als auch in der Wirtschaft Menschen, die sehr kompetent Meinungsumfragen durchführen. Wenn Jurist:innen alleine die Kompetenz fehlt (der Regelfall), ist eine Kooperation absolut notwendig und sinnvoll.
- Selbst Kompetenzen aufbauen. Das ist schwierig und langwierig, kann aber vor allem für Rechtswissenschaftler:innen sinnvoll und gewinnbringend sein.
- Ehrlich sein. Auch nicht-repräsentative Umfragen können nützlich sein und Probleme aufzeigen.
- Die Finger davon lassen. Wenn man weder mit Expert:innen arbeiten will, noch sich die Kompetenzen aneignen, noch ehrlich sein will, sollte man lieber die Finger von Umfragen und quantitativer Forschung lassen.
Visuelle Heranführung an die Ziehung von Zufallsstichproben Link to heading
Die Ziehung von Stichproben klingt wie ein sehr abstraktes Thema, lässt sich aber mit wenig Code gut visuell darstellen und verstehen. In diesem Abschnitt geht es um die Funktionsweise und die Vorteile von Zufallsstichproben, verglichen mit Bequemlichkeitsstichproben. Im nächsten Abschnitt vertiefen wir das Prinzip dann mit der Analyse von Zahlen.
Generierung einer künstlichen Grundgesamtheit Link to heading
Um eine kontrollierte didaktische Umgebung zu haben, arbeiten wir mit einer künstlich generierten Grundgesamtheit mit genau bestimmten Eigenschaften. Als Grundgesamtheit generieren wir Daten für 1.000 synthetische Menschen. Wir nehmen an, dass sie nur zwei relevante Merkmale haben: Körpergröße und IQ.
Ich habe diese konkreten Merkmale ausgesucht, weil sie jeweils in etwa normalverteilt sind, viele Menschen sich darunter etwas vorstellen können und wir eine kleine data story damit erzählen können.
Die Zahl 1.000 wähle ich nur wegen den Grenzen der grafischen Darstellung. Sobald wir im Rest des Tutorials nur noch Zahlen betrachten arbeiten wir mit einer größeren Grundgesamtheit.
Die Art der Verteilung der Grundgesamtheit ist für die Hochrechnung von Zufallsstichproben meist unwichtig.10 In einem Tutorial für Einsteiger:innen ist die Normalverteilung aber visuell und konzeptionell am einfachsten verständlich und setzt keine erhebliche statistische Vorbildung voraus. Erstellen wir zunächst die Daten:
1height <- rnorm(1000, mean = 175, sd = 10)
2iq <- rnorm(1000, mean = 100, sd = 15)
3
4df.full <- data.frame(height, iq) # zu einer Tabelle ("data.frame") zusammenfügen
Verteilung der einzelnen Variablen der Grundgesamtheit Link to heading
Rufen wir uns zunächst die Verteilung der einzelnen Variablen in Erinnerung. Wir sehen bei beiden die weithin bekannte Glockenkurve der Normalverteilung.
df.full$iq bedeutet: wähle die Variable “iq” aus dem data.frame “df.full” aus.
1par(mfrow = c(1, 2)) # Diagramme nebeneinander anzeigen
2
3hist(df.full$iq, breaks = 30)
4hist(df.full$height, breaks = 30)

Gemeinsame Verteilung beider Variablen der Grundgesamtheit Link to heading
Jetzt zeigen wir die gemeinsame Verteilung beider Variablen an. Damit nähern wir uns dem Referenzklassenproblem. Hier visualisieren wir nur zwei Merkmale (bzw. Referenzklassen). Ab zwei Dimensionen wird die grafische Darstellung schwierig.
Wir sprechen in diesem Fall von einer mehrdimensionalen Normalverteilung.
Zur Erinnerung: Merkmale von Menschen sind nicht immer normalverteilt (z.B. Einkommen ist nicht normalverteilt), wir arbeiten hier nur zur Verständlichkeit mit Merkmalen die diese Verteilung folgen.
1plot(df.full$height, df.full$iq, xlim = c(140,210))

Stichprobe nach Zufallsprinzip Link to heading
Jetz wird es ernst. Wir ziehen aus der Tabelle der Grundgesamtheit 100 zufällig ausgewählte Zeilen mit 100 Körpergröße-IQ-Kombinationen (eine für jeden synthethischen Menschen), lassen uns die Indizes anzeigen und weisen diese einer neuen, kleineren Tabelle zu:
1sample <- sample(1000, 100)
2print(sample)
1## [1] 177 863 756 389 542 919 643 784 67 279 518 890 904 452 645 254 666 892
2## [19] 846 438 507 986 786 154 999 308 53 526 559 590 621 247 493 870 429 931
3## [37] 734 594 456 490 532 394 627 149 338 794 836 807 40 476 163 745 797 570
4## [55] 562 298 13 512 3 551 249 505 833 132 236 48 747 414 607 69 713 457
5## [73] 144 909 662 282 19 431 557 215 104 515 996 536 243 257 958 812 346 87
6## [91] 230 997 699 740 365 221 14 782 715 334
1df.sample <- df.full[sample,]
2head(df.sample, n = 10) # Erste 10 Werte zur Verständlichkeit anzeigen
1## height iq
2## 177 175.2740 98.17320
3## 863 150.6249 95.60315
4## 756 181.3444 97.77425
5## 389 182.0073 73.21327
6## 542 180.0001 88.28220
7## 919 165.9460 132.34241
8## 643 192.7113 105.27204
9## 784 161.5208 120.87938
10## 67 164.8530 106.06232
11## 279 175.0136 101.23866
Jetzt nehmen wir diese neue Tabelle mit den zufällig ausgewählten synthetischen Menschen und visualisieren sie:
1plot(df.sample$height, df.sample$iq, xlim = c(140,210))

Auf beiden Achsen einzeln und zusammen, Körpergröße und IQ, sieht die Stichprobe im Vergleich mit der Grundgesamtheit sehr repräsentativ aus, oder?
Stichprobe nach Bequemlichkeit Link to heading
Jetzt ziehen wir nochmal eine Stichprobe, aber verzerren diese absichtlich. Statt nach Zufall auszuwählen, sortiere ich die Tabelle nach Körpergröße und wähle die 100 körperlich größten synthetischen Menschen aus. Ist das realistisch? Denken Sie nur an Treffen von Managern. Dort werden sie nicht nur überwiegend Männer sehen, sondern sehr viele sehr große Menschen treffen.11
1df.full <- df.full[order(-height),]
2df.convenience <- df.full[1:100,]
Zeigen wir auch diese Stichprobe an, markieren Sie aber mit rot, damit die Verzerrung besonders gut in Erinnerung bleibt.
1plot(df.convenience$height, df.convenience$iq, xlim = c(140,210), col = "red")
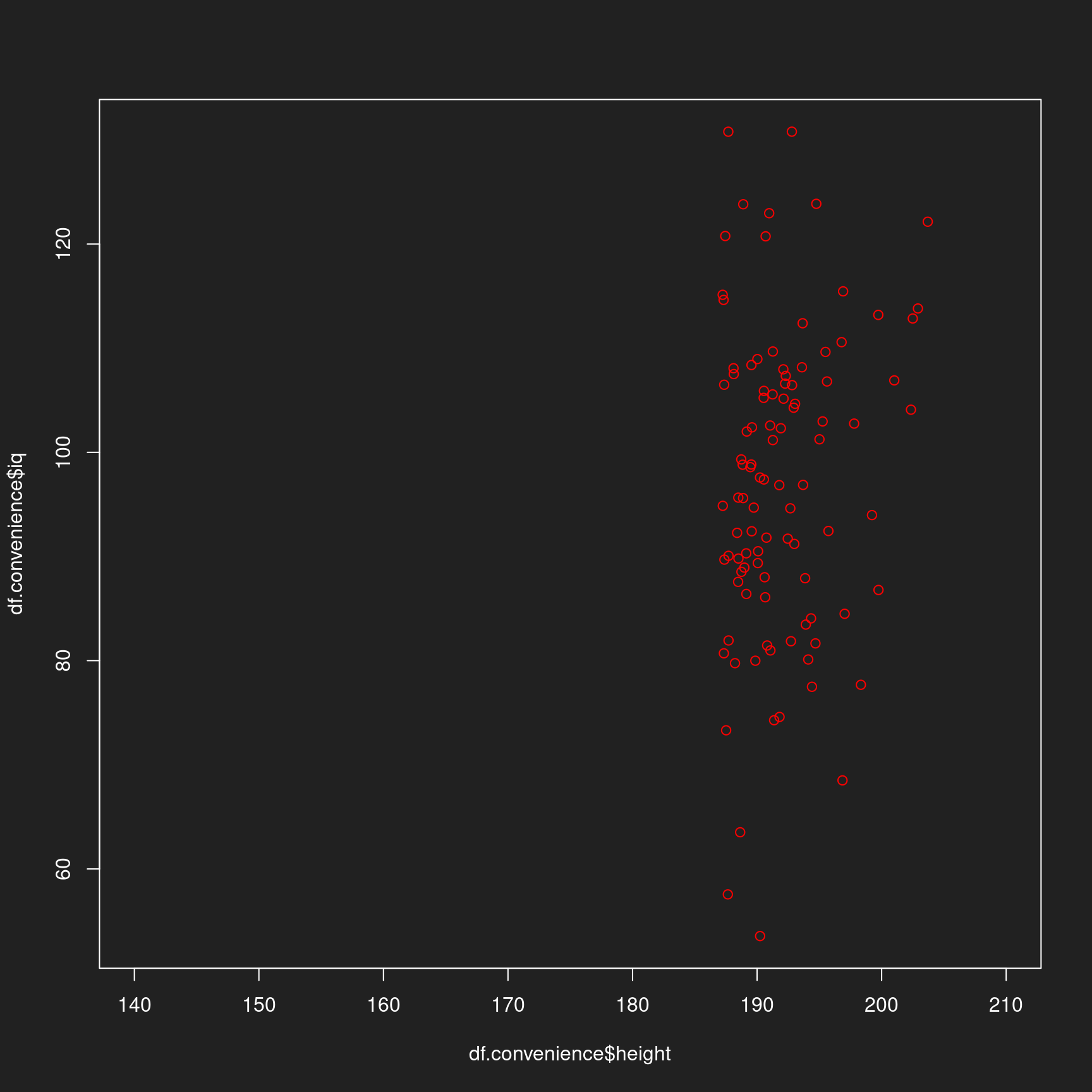
In diesem synthetischen Beispiel sind die Variablen der Einfachhheit halber unkorreliert, d.h. ihre Werte hängen nicht voneinander ab. In der Realität sind IQ und Körpergröße aber schwach korreliert.
Bei einer Korrelation zwischen Variablen (z.B. zwischen Körpergröße und Gehalt) würde diese verzerrte Stichprobe nach Körpergröße auch zu einer Verzerrung der Messung der anderen Variable (z.B. Gehalt) führen. Mit anderen Worten: wenn Sie einen Raum voller Top-Manager auf der Münchener Sicherheitskonferenz nach ihrem Gehalt befragen, werden Sie nicht viel über das repräsentative Gehalt in Deutschland erfahren.
Stichproben: Intuition mit Zahlen Link to heading
Grundgesamtheiten erstellen Link to heading
Nachdem wir uns der Idee der Zufallsstichprobe in grafischer Form genähert haben, entwickeln wir als Nächstes die Intuition mit Zahlen.
Wir erstellen zwei klassische Verteilungen, Normalverteilung und Log-Normalverteilung, bekannt aus dem Tutorial Verteilungen und Lageparameter. Diese Verteilungen sind unsere Grundgesamtheiten aus denen wir Stichproben ziehen werden. Die Normalverteilung entspricht dem IQ-Beispiel der grafischen Verteilung.
Diesesmal erstellen wir Grundgesamtheiten mit 10.000 Werten, weil wir die Rohdaten nicht mehr visualisieren werden.
1# Normalverteilung
2normal <- rnorm(10000, mean = 100, sd = 15)
3
4# Log-Normalverteilung
5lognorm <- rlnorm(10000, meanlog = 4.47, sdlog = 0.5)
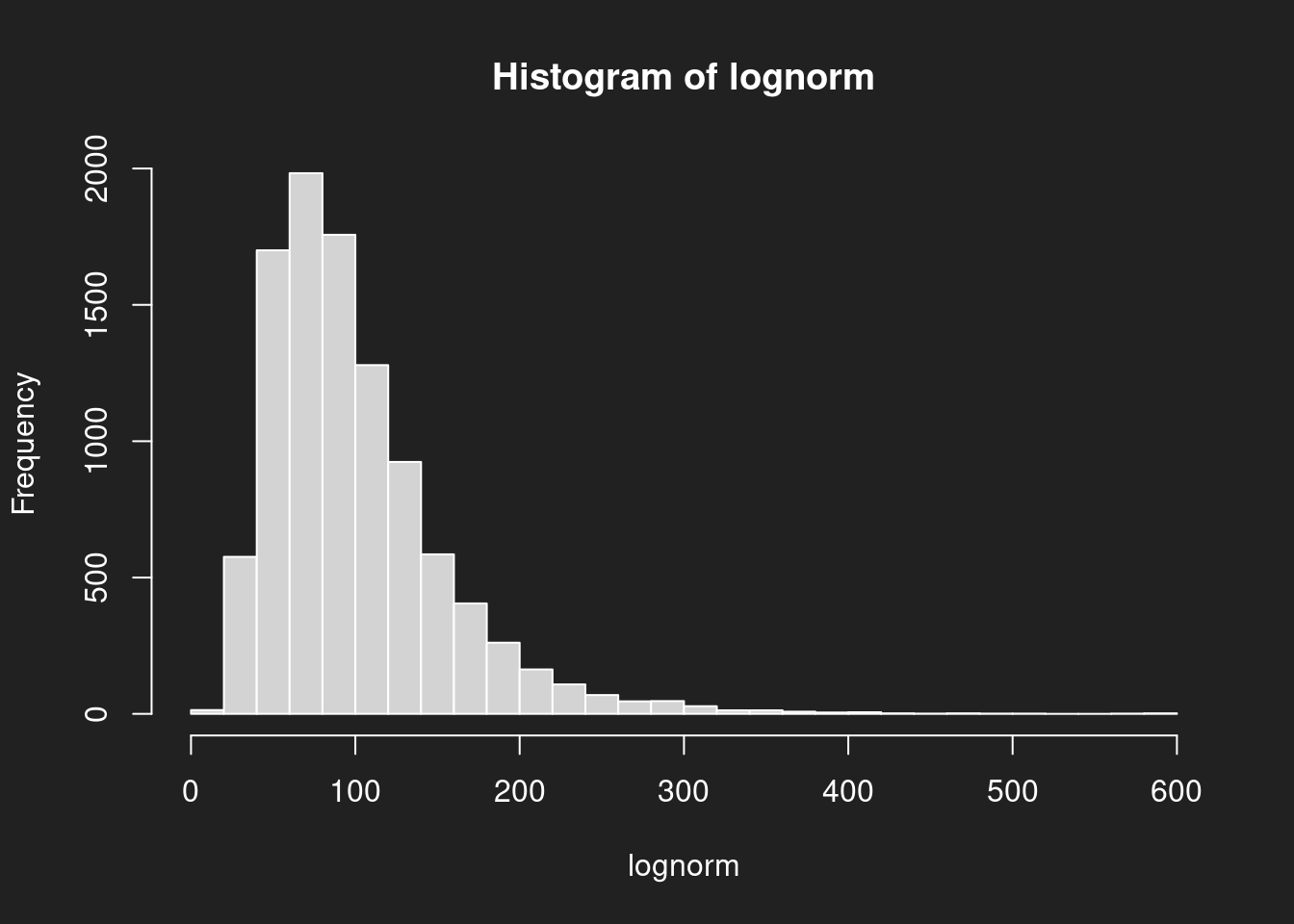
Verteilungen der Grundgesamtheiten visualisieren Link to heading
Wir sollten uns das Aussehen der Verteilungen auch noch einmal in Erinnerung rufen, denn es hilft bei der Interpretation.
1hist(normal, breaks = 30)

1hist(lognorm, breaks = 30)
Mittelwerte der Grundgesamtheiten Link to heading
In diesem Teil des Tutorials arbeiten wir mit dem arithmetischen Mittel, auch Mittelwert oder Durchschnitt genannt.
Aus den Diagrammen wissen wir, dass der Mittelwert bei der Beschreibung der Normalverteilung sehr hilfreich ist. Bei der Log-Normalverteilung auch, der Ausreißer wegen aber etwas weniger als bei der Normalverteilung.
Die Arbeit mit synthetischen Daten bietet uns einen riesigen Vorteil: wir kennen die echten Mittelwerte der Grundgesamtheiten und können dadurch die Güte unserer Stichproben beurteilen. Wir berechnen sie mit mean().
1mean(normal)
1## [1] 99.9197
1mean(lognorm)
1## [1] 98.46013
Mittelwert einer Stichprobe (Normalverteilung) Link to heading
Wir ziehen Stichproben aus der Grundgesamtheit, berechnen den Mittelwert der Stichprobe und vergleichen diese mit dem Mittelwert der Grundgesamtheit. Je näher wir am echten Wert der Grundgesamtheit sind, desto besser ist unsere Stichprobe.
sample(normal, 100)wählt 100 zufällige Werte aus der Grundgesamtheit ausmean()berechnet den Mittelwert
Ich habe beide Funktionen ineinander gesteckt, damit Sie alles in einer Zeile ausführen können. Der Fachbegriff dafür ist Komposition von Funktionen.
Probieren sie die Zeile mehrfach aus! Jedesmal wird eine neue Stichprobe gezogen und die Ergebnisse ändern sich leicht. Sie können dadurch simulieren, wie das Ergebnis bei mehrfacher Stichprobenziehung variiert und wie nah und fern sie mit jeder Schätzung am Original liegen.
1mean(sample(normal, 100))
1## [1] 101.159
1mean(sample(normal, 100))
1## [1] 100.2272
1mean(sample(normal, 100))
1## [1] 103.0665
1mean(sample(normal, 100))
1## [1] 98.78024
1mean(sample(normal, 100))
1## [1] 100.2124
Für eine Stichprobe von nur 100 Werten aus 10.000 Werten ziemlich gut, oder?
Mittelwert einer Stichprobe (Log-Normalverteilung) Link to heading
Und jetzt bei der Log-Normalverteilung. Hier ist die Schätzung herausfordernder als bei der Normalverteilung.
Führen Sie diese Zeile mehrfach nacheinander aus! So bekommen Sie ein Gefühl für die Varianz um den wahren Mittelwert, der durch die Unsicherheit der Stichprobenziehung erzeugt wird.
1mean(sample(lognorm, 100))
1## [1] 102.7188
1mean(sample(lognorm, 100))
1## [1] 99.43015
1mean(sample(lognorm, 100))
1## [1] 98.25377
1mean(sample(lognorm, 100))
1## [1] 96.54242
1mean(sample(lognorm, 100))
1## [1] 95.83354
Bei der Log-Normalverteilung liegt man manchmal schon deutlicher daneben, oder? Das liegt an der Schiefe der Verteilung. Bei nicht-normalen Verteilungen braucht es eine größere Stichprobengröße um den Mittelwert gut zu treffen. So gelangen wir bei 1.000 Werten schon viel besser dran.
1mean(sample(lognorm, 1000))
1## [1] 98.59359
Zum Vergleich der echte Mittelwert der log-normal-verteilten Grundgesamtheit:
1mean(lognorm)
1## [1] 98.46013
Willkürliche Stichproben Link to heading
Wenn Sie jetzt wie oben willkürliche Stichproben ziehen, beispielsweise die höchsten 100 Werte nehmen, werden Sie deutlich danebenliegen.
1# Verteilungen sortieren
2normal.sort <- sort(normal)
3lognorm.sort <- sort(lognorm)
4
5# 100 höchste Werte auswählen
6normal.opportunity <- tail(normal.sort, n = 100)
7lognorm.opportunity <- tail(lognorm.sort, n = 100)
8
9# Mittelwert berechnen
10mean(normal.opportunity)
1## [1] 140.0062
1mean(lognorm.opportunity)
1## [1] 343.0442
Das soll als besonders abschreckendes Beispiel dienen. Das Problem an nicht-Zufallsstichproben ist aber ein anderes: man weiß einfach nicht wie verzerrt sie sind. Darauf zu hoffen, dass die Stichprobe schon irgendwie “durchmischt” ist, ist methodisch nicht vertretbar.
Zusammenfassung Link to heading
Wir haben aus synthetischen Grundgesamtheiten Zufallsstichproben und willkürliche Stichproben gezogen. Die Zufallsstichproben treffen den Mittelwert sehr gut (Normalverteilung) oder gut genug mit entsprechender Stichprobengröße (Log-Normalverteilung).
Willkürlich Stichproben können sehr verzerrt sein oder auch nicht. Wir wissen es einfach nicht und das ist das Problem.
Das Bootstrap-Verfahren Link to heading
Einführung Link to heading
Wir haben im vergangenen Abschnitt gesehen, dass mehrere Stichproben den eigentlichen Mittelwert nie genau treffen, sondern kleinere oder größere Abweichungen aufzeigen. Wie können wir aber herausfinden wie gut unsere Schätzung ist, wenn wir nur eine Stichprobe haben und nicht einfach neue Stichproben aus der Grundgesamtheit ziehen können (z.B. aus Kostengründen)?
Das Bootstrap-Verfahren ist eine der beeindruckendsten Erfindungen der Statistik und gleichzeitig eine Systematisierung und Erweiterung von dem, was wir bisher besprochen haben. Das Bootstrap-Verfahren wird manchmal auch als Münchhausen-Methode bezeichnet, weil das Vorgehen an Baron Münchhausen erinnert, der sich einst angeblich an den eigenen Haaren aus dem Sumpf zog.
Die Methode wurde von Bradley Efron (1979) erfunden.12
Ich bespreche hier das Bootstrap-Verfahren und nicht klassische Verfahren wie den t-test, weil Bootstrap keine komplizierten mathematischen Erklärungen erfordert, einfacher auszuprobieren ist und günstigere theoretische Eigenschaften hat. Insbesondere kann man mit Bootstrap nicht nur den Mittelwert der Grundgesamtheit schätzen, sondern viele andere Statistiken (z.B. den Median oder Quartile).
Vielleicht erinnern sie sich an die nervigen Urnen-Beispiele der Schule, bei denen man aus Urnen farbige Kugeln zieht und diese immer wieder zurücklegt, bevor man erneut zieht? Niemand spielt in der Praxis mit Urnen, aber das Resampling ist die Grundlage des Bootstrap-Verfahrens.
Die Methode funktioniert wie folgt:
- Grundlage des Bootstrap-Verfahrens ist eine Zufallsstichprobe aus der Grundgesamtheit.
- Aus dieser Zufallsstichprobe werden erneut (!) Stichproben gezogen, aber jedes mal mit Zurücklegen. Wir nennen diese neuen Stichproben Bootstrap-Stichproben oder Resamples.
- Aus den Bootstrap-Stichproben wird jeweils ein Lageparameter berechnet, z.b. der Median oder der Mittelwert.
- Die vielen einzelne Lageparameter aus dem 3. Schritt werden in einer Verteilung zusammengefasst. Durch diese Verteilung können wir die Unsicherheit der Schätzung des Parameters aus der Grundgesamtheit quantifizieren.
Anders als bei unseren Versuchen mit einzelnen Stichproben ist Bootstrap für eine Situation entwickelt worden, bei der es nicht möglich ist, neue Stichproben direkt aus der Grundgesamtheit zu ziehen.
Stattdessen nutzt man die originale Stichprobe als Ersatz-Grundgesamtheit, unter der Annahme, dass die Varianz in der Grundgesamtheit so oder so ähnlich auch in der Stichprobe abgebildet wird. Vielfaches Resampling erlaubt dann eine Schätzung der Unsicherheit bei der Bestimmung der Parameter der Grundgesamtheit.
Zufallsstichproben ziehen Link to heading
Als Grundlage des Bootstrap ziehen wir zwei Zufallsstichproben mit unterschiedlichen Stichprobengrößen:
- N = 100
- N = 1000
Wir sehen uns damit an, wie sich die Größe der ursprünglichen Stichproben auf die Genauigkeit der Schätzung auswirkt. Wir nutzen wieder die Log-Normalverteilung, die uns oben schon zeigte, wie die Erhöhung der Stichprobengröße auch die Genauigkeit der Schätzung verbessert.
1sample.random100 <- sample(lognorm, size = 100)
2sample.random1000 <- sample(lognorm, size = 1000)
Bootstrap durchführen Link to heading
Der Code für den Bootstrap ist ein wenig komplizierter.
sample(sample.random100, size = 100, replace = TRUE)erstellt die einzelnen Resamples. Achtung:sizemuss exakt der Größe der originalen Stichprobe entsprechen undreplace = TRUEführt die Ziehung mit Zurücklegen durch.mean()berechnet den Mittelwert des Resamples.replicate()wiederholt diesen Resampling-Schrittn = 10000mal.
1bootstrap100 <- replicate(n = 10000,
2 expr = mean(sample(sample.random100,
3 size = 100,
4 replace = TRUE)))
5
6
7bootstrap1000 <- replicate(n = 10000,
8 expr = mean(sample(sample.random1000,
9 size = 1000,
10 replace = TRUE)))
Bootstrap-Histogramme Link to heading
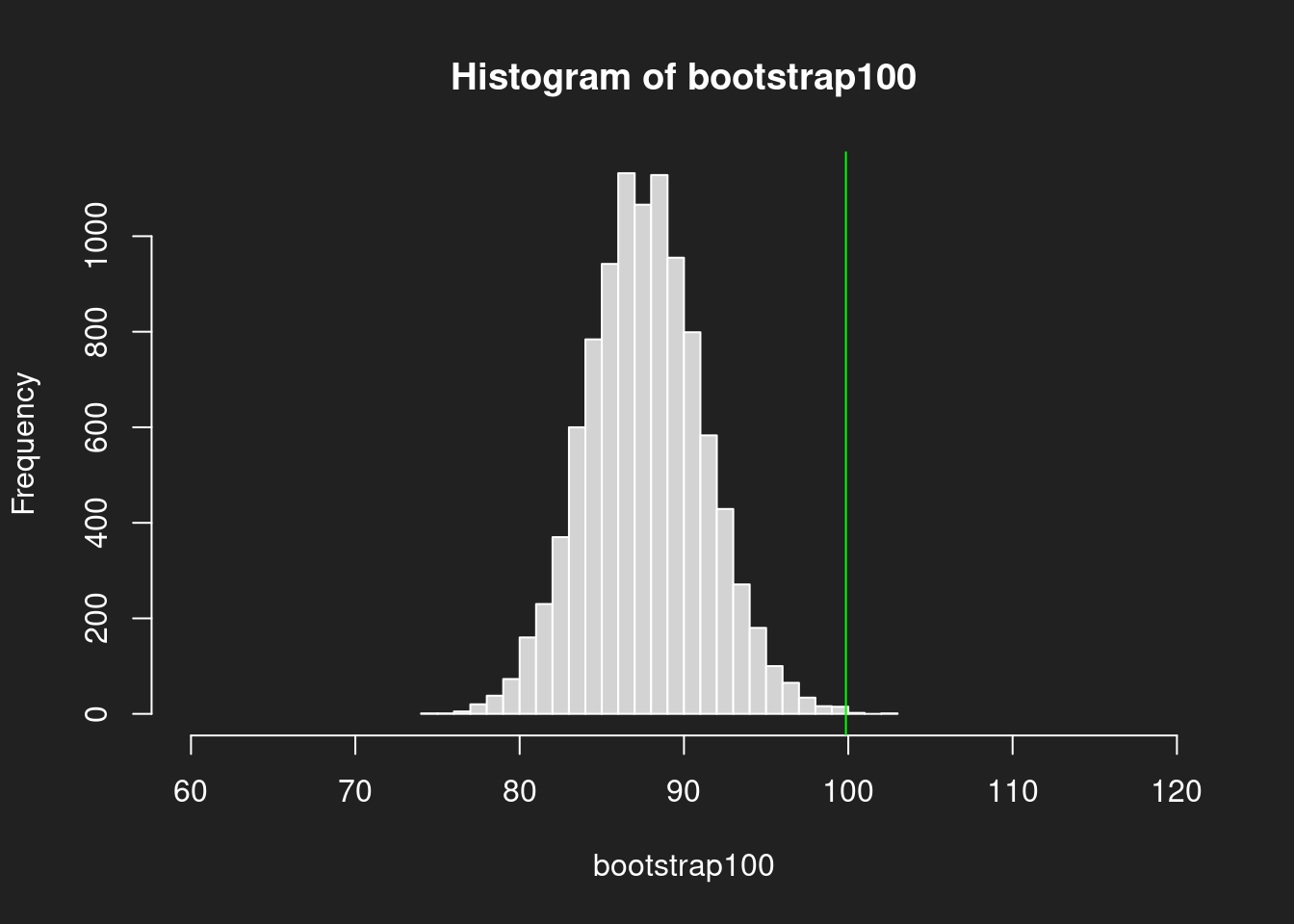
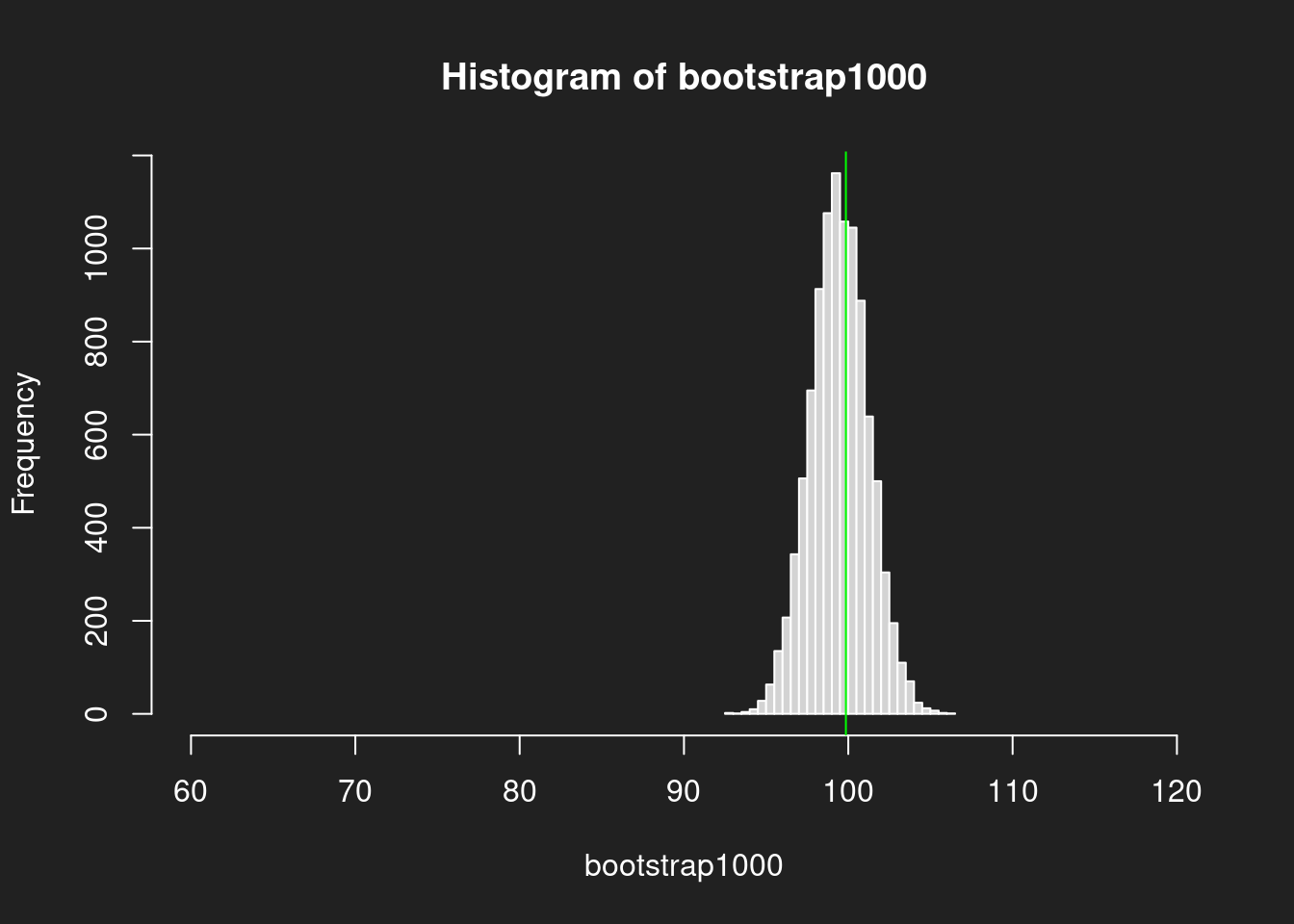
Sehen wir uns die Verteilungen an! Wir berechnen Histogramme für die Bootstrap-Ergebnisse der unterschiedlich großen Stichproben um zu zeigen wieviel besser eine 1000er-Stichprobe den Mittelwert im Vergleich zur 100er-Stichprobe trifft.
Wir zeichnen auch jeweils den echten Mittelwert der Grundgesamtheit in grün ein, damit wir die Güte der Stichprobe grafisch beurteilen können.
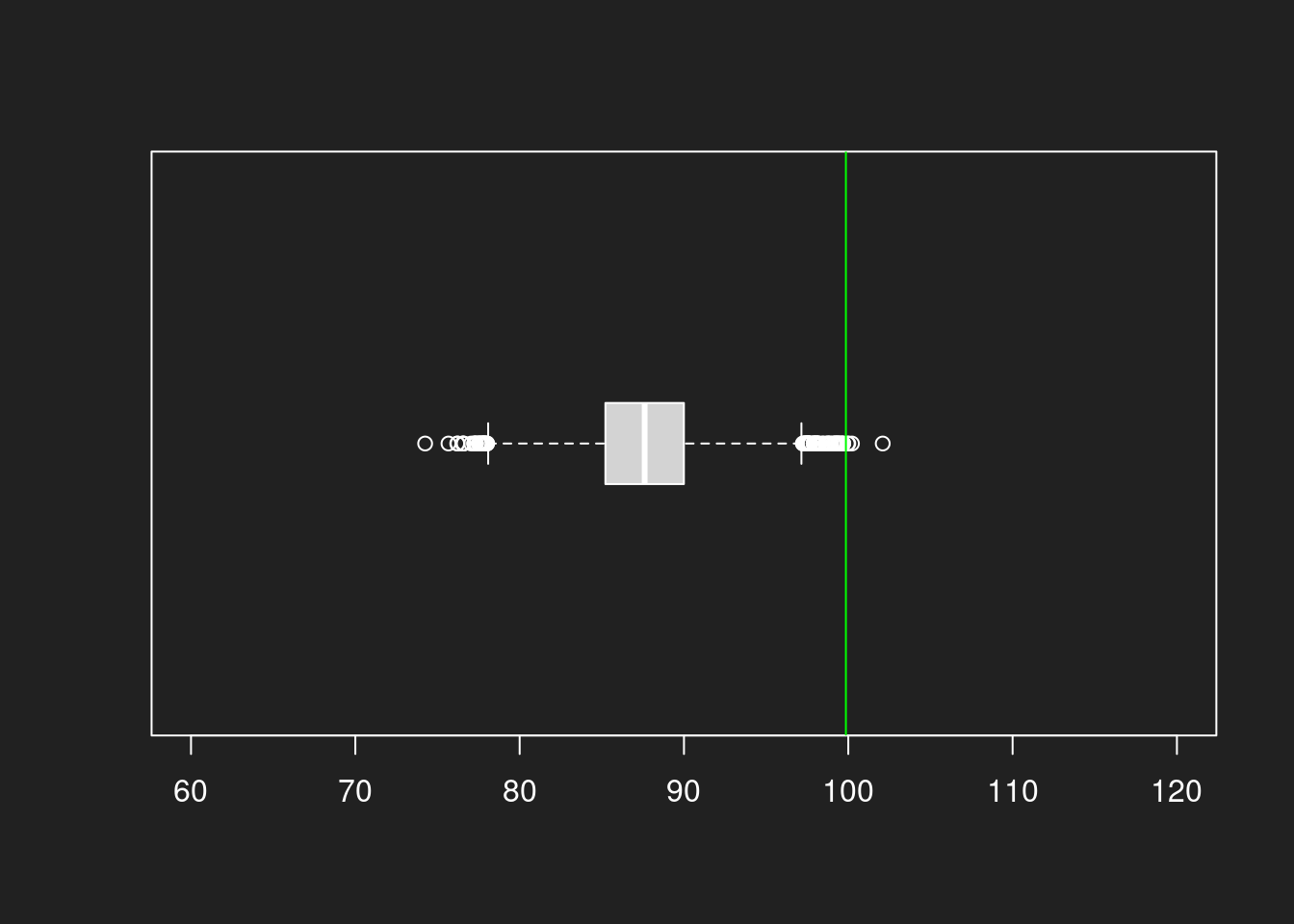
Histogramm aus Stichprobe mit N = 100 Link to heading
1hist(bootstrap100, breaks = 30, xlim = c(60, 120))
2abline(v = mean(lognorm), col = "green")
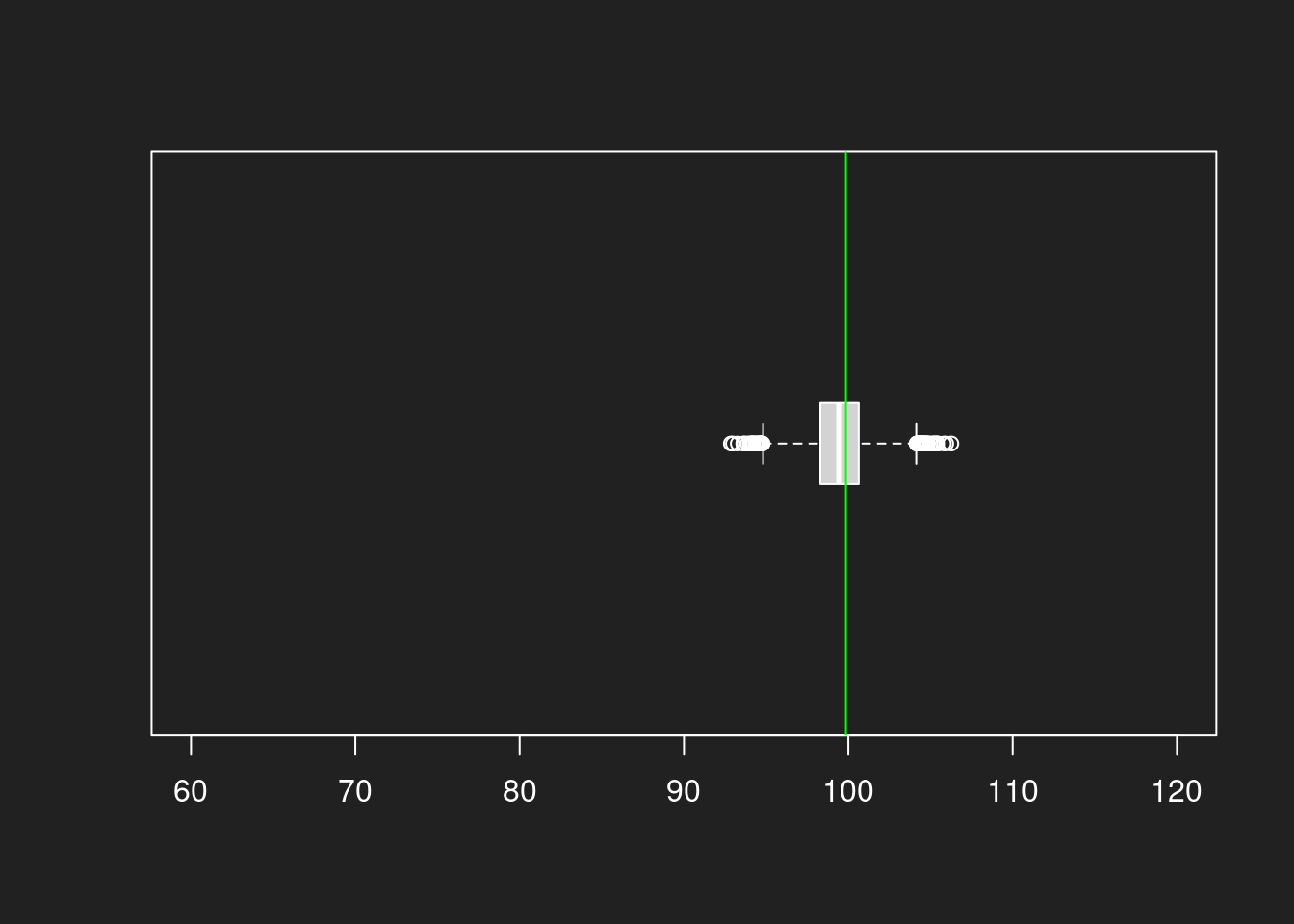
Histogramm aus Stichprobe mit N = 1000 Link to heading
1hist(bootstrap1000, breaks = 30, xlim = c(60, 120))
2abline(v = mean(lognorm), col = "green")
Zusammenfassung Bootstrap-Histogramme Link to heading
Wir sehen ganz deutlich, wie die Schätzungen beim 1000er-Histogramm viel näher um den eigentlichen Mittelwert gruppiert sind. Beim 100er-Histogramm liegen wir viel öfter daneben.
Bootstrap-Boxplots Link to heading
Und nun das gleich nochmal mit Boxplots. Vergessen was Boxplots sind? Das Tutorial Verteilungen und Lageparameter hilft weiter.
Boxplot aus Stichprobe mit N = 100 Link to heading
1boxplot(bootstrap100, horizontal = TRUE, boxwex = 0.3, ylim = c(60, 120))
2abline(v = mean(lognorm), col = "green")
Boxplot aus Stichprobe mit N = 1000 Link to heading
1boxplot(bootstrap1000, horizontal = TRUE, boxwex = 0.3, ylim = c(60, 120))
2abline(v = mean(lognorm), col = "green")
Zusammenfassung Bootstrap Boxplots Link to heading
Die Boxplots zeigen wie die Histogramme die höhere Güte der Stichprobe mit N = 1000. Wir treffen selbst bei der Log-Normalverteilung den Mittelwert sehr gut und die Varianz ist auch viel geringer. Und das alles mit einer einzigen Stichprobe!
Zusammenfassung Tutorial Link to heading
Wir haben in diesem Tutorial sehr viel über Stichproben, Grundgesamtheiten und Repräsentativität gelernt.
Wir haben Grundgesamtheiten als Menge aller für die Forschungsfrage relevanten Einheiten kennengelernt. Stichproben sind eine Teilmenge der anvisierten Grundgesamtheit. Eine sauber gewählte repräsentative Stichprobe lässt Schlüsse auf die Grundgesamtheit zu.
Qualitativ hochwertige Repräsentativität können nur Zufallsstichproben herstellen. Statistische Korrekturen sind bei wohldefinierten Problemen und mit viel Kompetenz möglich, aber riskant. Der Grund dafür liegt im Referenzklassenproblem: jede untersuchte Einheit kann in unendlich viele Merkmale/Referenzklassen eingeteilt werden. Die relevanten Merkmale zu bestimmen ist oft unmöglich und nur Zufallsstichproben verteilen sie alle gleich.
Danach haben wir den Aufstieg und Niedergang des Literary Digest betrachtet, ein Magazin welches trotz einer gewaltigen Stichprobengröße von 2,27 Millionen einen falschen Schluss aus einer nicht-repräsentative Umfrage zog, seinen Ruf verlor und schließen musste. Die Bundesrechtsanwaltskammer (BRAK) ist ein modernes Pendant hierzu und vertraut in seiner Interessenvertretung auf ähnlich fehlerhaft gezogene Stichproben, noch dazu mit einer viel kleineren Stichprobengröße.
Nach dem theoretischen Teil haben wir das Prinzip der Zufallsstichprobe grafisch betrachtet und mit einer verzerrten Stichprobe verglichen. Im Anschluss dann das gleiche intuitiv mit Zahlen und einer viel größeren Zahl der Einheiten in der Grundgesamtheit. Wir haben gelernt, dass Zufallsstichproben grundsätzlich gut funktionieren und Repräsentativität herstellen, ohne etwas über die eigentliche Forschungsfrage wissen zu müssen.
Schließlich haben wir noch das Bootstrap-Verfahren ausprobiert, um die Qualität zwischen verschiedenen Stichprobengrößen genauer zu verstehen. Eine Stichprobe mit N = 100 trifft in unserem Beispiel den eigentlichen Mittelwert nicht besonders gut und weist viel Varianz auf. Mit einer Stichprobe von N = 1000 treffen wir den Mittelwert aber sehr genau und haben einen geringen Schätzfehler. Aus diesen und anderen Gründen wird in modernen Umfragen oft mit einer Stichprobengröße von ca. 1000 gearbeitet.
Das war ein sehr langes Tutorial, aber Sie haben es bis zum Ende geschafft. Herzlichen Glückwunsch!
Informationen zur strengen Replikation Link to heading
Dieses Tutorial wurde zuletzt aktualisert am: 2026-02-08.
1sessionInfo()
1## R version 4.2.2 Patched (2022-11-10 r83330)
2## Platform: x86_64-pc-linux-gnu (64-bit)
3## Running under: Debian GNU/Linux 12 (bookworm)
4##
5## Matrix products: default
6## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
7## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.21.so
8##
9## locale:
10## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
11## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
12## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
13## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
14## [9] LC_ADDRESS=C LC_TELEPHONE=C
15## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
16##
17## attached base packages:
18## [1] stats graphics grDevices datasets utils methods base
19##
20## other attached packages:
21## [1] knitr_1.48
22##
23## loaded via a namespace (and not attached):
24## [1] bookdown_0.40 digest_0.6.37 R6_2.5.1 lifecycle_1.0.4
25## [5] jsonlite_1.8.8 evaluate_0.24.0 highr_0.11 blogdown_1.19
26## [9] cachem_1.1.0 rlang_1.1.4 cli_3.6.3 renv_1.0.7
27## [13] jquerylib_0.1.4 bslib_0.8.0 rmarkdown_2.28 tools_4.2.2
28## [17] xfun_0.47 yaml_2.3.10 fastmap_1.2.0 compiler_4.2.2
29## [21] htmltools_0.5.8.1 sass_0.4.9
-
Siehe BVerfG, Urteil des Zweiten Senats vom 19. Dezember 2023, 2 BvC 4/23. ↩︎
-
Achtung: Der Mathematik ist die Forschungsfrage völlig egal. Sie beantwortet Fragen zu Bundesbürger:innen und Kaulquappen komplett gleich und stört sich nicht daran, wenn jemand versucht von Kaulquappen auf Bundesbürger:innen zu schließen. ↩︎
-
Die geographische Abdeckung ist aber nicht überall gleich gut. So haben Europa und Amerika in der Geschichtsforschung deutlich mehr Aufmerksamkeit erfahren als Afrika. ↩︎
-
Tatsächlich war das Verhältnis zum Endes des Jahres 2022 in Deutschland etwa 971 Männer zu 1000 Frauen, wie das Statistische Bundesamt berichtet. Das ist nicht über all so. In China besteht beispielsweise aufgrund der langjährigen Ein-Kind-Politik und verbreiteten Femiziden ein spürbarer Überschuss an Männern. ↩︎
-
Gelman, A., & Hennig, C. (2017). Beyond subjective and objective in statistics. Journal of the Royal Statistical Society Series A: Statistics in Society, 180(4), 967-1033. ↩︎
-
Wang, W., Rothschild, D., Goel, S., & Gelman, A. (2015). Forecasting elections with non-representative polls. International Journal of Forecasting, 31(3), 980-991. ↩︎
-
1936 gab es nur 48 US-Bundesstaaten. Alaska und Hawaii kamen erst 1959 hinzu. Heute haben die USA 50 Bundesstaaten. ↩︎
-
Ich nenne es mal Irrtümer. Es lassen sich auch unfreundlichere Bewertungen finden. ↩︎
-
In den Detail-Ergebnissen ist das Feld für “Einladungen” leer und es werden nur “Besucher” und “Teilnehmer” erfasst. Auch sind ~10.000 Teilnehmer eine sehr ungewöhnliche Stichprobengröße. Auch sonst beruft sich die BRAK immer auf die tatsächlichen Teilnehmer:innen einer Umfrage um die Repräsentativität zu begründen. ↩︎
-
Es gibt Verteilungen, die mit den herkömmlichen Verfahren nicht gut schätzbar sind, z.B. die Cauchy-Verteilung. Das liegt am zentralen Grenzwertsatz, der nur gilt, wenn für die Verteilung der Grundgesamtheit der Mittelwert und die Standardabweichung definiert und endlich sind. Da man die echte Verteilung einer Grundgesamtheit in der Regel nicht kennt, beten die meisten Statistiker:innen vermutlich einfach, dass ihre untersuchte Grundgesamtheit nicht einer abnormen Verteilung folgt. ↩︎
-
Siehe beispielsweise Lindqvist, E. (2012). Height and leadership. Review of Economics and statistics, 94(4), 1191-1196. ↩︎
-
Efron, B. (1979). Bootstrap methods: Another look at the jackknife. The Annals of Statistics. 7 (1): 1–26. ↩︎