Key Word in Context (KWIC) Analyse und Lexical Dispersion Plots
Überblick Link to heading
Dieses Tutorial stellt die Methode der Key Word in Context (KWIC) Analyse im Zusammenhang mit Programmcode in der Programmiersprache R vor. Es führt Sie durch den gesamten Workflow, vom ersten Kontakt mit dem Datensatz auf Zenodo, bis zur abschließenden Interpretation und Visualisierung der Ergebnisse. Vertiefungshinweise in blauen Boxen erläutern Hintergründe zum technischen Vorgehen.
Zielgruppe sind Jurist:innen, die erste Erfahrungen mit der maschinellen Analyse von Texten sammeln wollen. Analysiert werden Urteile und Beschlüsse aus der amtlichen Sammlung des Bundesverfassungsgerichtes (BVerfGE). Dabei reduzieren wir eine gewaltige Textmenge auf ein für die menschliche Weiternutzung nützliches Maß.
Eine KWIC-Analyse bietet Jurist:innen folgenden Mehrwert:
- Schnelles Auffinden relevanter Texte
- Schnelles Auffinden relevanter Textstellen in relevanten Texten
- Vollständigkeit der Auswertung einer Textsammlung mittels Konkordanztabellen
- Einfache visuelle Möglichkeit der Kommunikation der Ergebnisse für ein nicht-technisches Publikum
KWIC-Analysen sind eine bewährte Standardmethode im Natural Language Processing (NLP), der maschinellen Verarbeitung von Sprache. Bei einer KWIC-Analyse geht es um das Auffinden von relevanten Textstellen in einem Textkorpus durch ein oder mehrere Schlüsselworte bzw. Schlüsselphrasen. Dabei wird das Schlüsselwort (keyword) lokalisiert und ein Kontextfenster (in-context) extrahiert. Lexical Dispersion Plots bieten eine überzeugende und einfach zu interpretierende Visualisierung der Ergebnisse einer KWIC-Analyse.
Im juristischen Kontext ist die KWIC-Analyse von hoher Bedeutung, weil die Rechtswissenschaft eine Schlagwortwissenschaft ist. Juristische Probleme drehen sich oft um die Auslegung von ganz bestimmten Begriffen. Zudem sind die Begriffe in der Rechtswissenschaft oft lang, übermäßig kompliziert und im normalen Sprachgebrauch selten zu finden (Beispiel: “Fortsetzungsfeststellungsklage”), dafür maschinell umso einfacher.
Die Key Word in Context (KWIC) Methode hatte ich bereits 2022 in der Legal Tribune Online (LTO) im Artikel Legal Data Science — Teil II: Wie man sie nutzen kann einem breiten Fachpublikum vorgestellt.
Inhaltsverzeichnis Link to heading
Installation von R Packages Link to heading
Wir benötigen die Packages {zip} , {quanteda} und {quanteda.textplots} für dieses Tutorial. Falls Sie diese noch nicht installiert haben, tun Sie das bitte jetzt.
1install.packages("zip")
2install.packages("quanteda")
3install.packages("quanteda.textplots")
Über den Datensatz Link to heading
Corpus der amtlichen Entscheidungssammlung des Bundesverfassungsgerichts (C-BVerfGE)
In diesem Tutorial arbeiten wir mit einem bereits intensiv aufbereiteten Datensatz, der alle durch das BVerfG auf seiner Internetpräsenz veröffentlichten Entscheidungen der amtlichen Sammlung (BVerfGE) enthält. Das Vollzitat lautet:
Fobbe, S. (2023). Corpus der amtlichen Entscheidungssammlung des Bundesverfassungsgerichts (C-BVerfGE) (2023-02-20) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.7655163
“Korpus” oder “Korpora” (alternativ mit “c” geschrieben) sind Datensätze, die primär aus Texten bestehen.
Die Dokumentation des Datensatzes findet sich im Codebook und kann auf Zenodo eingesehen werden. Codebooks sind eine Art “Bedienungsanleitung” zu Datensätzen, die über ihren Inhalt und wesentliche Eigenschaften informieren. Sie werden darin auch weitere nützliche Visualisierungen finden.
Datensatz herunterladen und entpacken Link to heading
1library(zip)
1##
2## Attaching package: 'zip'
1## The following objects are masked from 'package:utils':
2##
3## unzip, zip
1# Datensatz Herunterladen
2download.file(url = paste0("https://zenodo.org/records/7655163/files/",
3 "C-BVerfGE_2023-02-20_DE_CSV_Datensatz.zip"),
4 destfile = "C-BVerfGE_2023-02-20_DE_CSV_Datensatz.zip")
5
6
7# Datensatz entpacken
8unzip(zipfile = "C-BVerfGE_2023-02-20_DE_CSV_Datensatz.zip")
Dieser Code-Abschnitt lädt die CSV-Fassung des Datensatzes automatisiert herunter und entpackt ihn im lokalen Arbeitsordner (working directory). Das muss nicht zwingend durch Code geschehen. Sie dürfen das gerne auch manuell tun. Ich präsentiere aber den Code, um einen voll automatisierten und reproduzierbaren Workflow zu zeigen.
Ich nutze die Funktion paste0() um die sehr lange URL aus zwei Teilen zusammenzusetzen: dem Zenodo-Eintrag und dem Dateinamen. Das geschieht einerseits aus optischen Gründen, um die überlange Zeile zu brechen, andererseits um schon einmal anzudeuten, dass komplexe URLs auch automatisch konstruiert werden können (beispielsweise für das Web Scraping wichtig).
Falls Sie den Datensatz manuell herunterladen und entpacken, achten Sie bitte darauf, dass im Anschluss die Datei C-BVerfGE_2023-02-20_DE_CSV_Datensatz.csv im gleichen Ordner ist, in dem sie arbeiten und ihre R Session geöffnet haben. Sie können das aktuelle working directory mit getwd() herausfinden. In diesem Ordner muss sich die CSV-Datei befinden.
Vertiefung: Entpacken von ZIP files in R
Wieso habe ich oben das package {zip}
verwendet, obwohl R eine eingebaute unzip()-Funktion hat? Die in R mitgelieferte Funktion verbindet sich leider nur mit dem System-Tool unter Linux und kann daher nicht auf anderen Betriebssystemen verwendet werden. Das {zip}
package funktioniert auf allen Plattformen, inklusive Windows und Mac.
Einlesen des Datensatzes Link to heading
1bverfg <- read.csv(file = "C-BVerfGE_2023-02-20_DE_CSV_Datensatz.csv",
2 header = TRUE)
read.csv() liest die CSV-Datei ein und wir weisen das Ergebnis dem Objekt bverfg zu. Wir erhalten damit ein data.frame, die typische Form einer Tabelle in R.
header = TRUE informiert die Funktion, dass die erste Zeile der CSV-Datei die Namen der Variablen enthält. Normalerweise ist dieser Parameter immer auf TRUE gesetzt, aber ich habe ihn hier zur Klarstellung mit aufgenommen.
Vertiefung: CSV-Dateien
CSV-Dateien (RFC 4180) sind ein sehr einfaches Datei-Format für Tabellen. Eine CSV-Datei ist eine Text-Datei in der jede Zeile einer Reihe entspricht und einzelne Zellen der Reihen durch Kommata voneinander getrennt sind. CSV steht für “comma separated values”.
Daraus ergibt sich eine Tabelle, die Sie mit Software wie Excel und Libre Office öffnen können. Es gibt auch Varianten von CSV, die Semikolon-separiert oder Tab-separiert (TSV) sind. Insbesondere Excel produziert in manchen europäischen Lokalisierungen Semikolon-separierte CSV-Dateien.
Key Word in Context Analyse (KWIC) Link to heading
Quanteda aktivieren Link to heading
1library(quanteda)
1## Package version: 4.1.0
2## Unicode version: 15.0
3## ICU version: 72.1
1## Parallel computing: disabled
1## See https://quanteda.io for tutorials and examples.
1library(quanteda.textplots)
Für die KWIC-Analyse verwenden wir das {quanteda} R package. Quanteda ist ein sehr gutes und umfangreiches Framework zur maschinellen Analyse von Texten, dem Natural Language Processing (NLP).
Wir binden auch schon einmal {quanteda.textplots} ein, eine Erweiterung zu Quanteda, die verschiedene Diagramme zur Visualisierung von NLP-Analysen bereitstellt.
Workflow Link to heading
Das Diagramm zeigt den NLP Workflow den wir gleich ausführen. Wir beginnen mit dem rohen Datensatz, erstellen ein Korpus-Objekt, tokenisieren dieses, führen eine KWIC-Analyse durch und visualisieren das Ergebnis als Lexical Dispersion Plot.
Normalerweise wird in NLP Workflows intensives Pre-Processing betrieben, bei diesem Datensatz hat das aber für Sie alle schon der Autor erledigt.
Korpus-Objekt erstellen Link to heading
1corpus <- corpus(x = bverfg)
Die Funktion corpus() erstellt aus einem data.frame (der klassischen Darstellung einer Tabelle in R) ein spezielles corpus-Objekt, mit dem Quanteda intern arbeitet. Ein dazu passendes data.frame muss die Variablen doc_id und text haben, um zu einem Korpus-Objekt transformierbar zu sein.
Alle anderen Variablen werden in “docvars” überführt, d.h. als Metadaten behandelt. Das Corpus der amtlichen Entscheidungssammlung des Bundesverfassungsgerichts (C-BVerfGE) ist bereits in diesem Format aufbereitet, sodaß Sie nichts weiter tun müssen, außer corpus() einmal aufzurufen.
Tokenisierung Link to heading
1tokens <- tokens(x = corpus)
Die Funktion tokens() erstellt aus einem corpus-Objekt ein tokens-Objekt. Die Tokenisierung ist ein Standardschritt in praktisch jedem NLP-Projekt.
Bei der Tokenisierung wird ein Fließtext (technischer: ein String) in einzelne Bestandteile (Tokens) zerlegt. In der Regel trennt man anhand von Leerzeichen. Das Ergebnis entspricht in westlichen Sprachen oft dem intuitiven Verständnis eines Wortes, kann aber auch davon abweichen, wenn im Text freistehende Zahlen, Sonderzeichen und andere spezielle Zeichenketten vorkommen.
Beispiel: der Text “Im Namen des Volkes” würde in vier Token zerlegt werden: “Im”, “Namen”, “des” und “Volkes”. Oft entfernt man in diesem Schritt auch Sonderzeichen, Zahlen, Emojis etc. Wir verzichten hier aber darauf, weil es für die KWIC-Analyse sinnvoller ist die Schlüsselwörter in ihrem originalen Kontext zu betrachten.
KWIC-Analyse durchführen Link to heading
1kwic <- kwic(x = tokens,
2 pattern = "Sicherungsverwahrung",
3 window = 8,
4 valuetype = "fixed",
5 case_insensitive = TRUE)
Die Funktion kwic() führt die Key Word in Context Analyse anhand eines Tokens-Objektes durch.
xist der zentrale Parameter, mit dem das zu nutzendetokens-Objekt definiert wird.pattern = "Sicherungsverwahrung"gibt den Suchbegriff an, der uns interessiert.window = 8ist die Anzahl der Tokens des Kontextfensters (vor und nach dem Treffer). Hier setzen wir 8 Tokens fest. Probieren Sie bei späteren Versuchen eine andere Anzahl aus und beobachten Sie, wie sich die Ergebnisse ändern.valuetype = "fixed"gibt an, dass wir nach einem festen Begriff suchen. Der Parameter kann auch aufregexoderglobgesetzt werden, um komplexere Suchausdrücke zu formulieren. Dafür sind aber vertiefte Kenntnisse erforderlich.case_insensitive = TRUEbedeutet, dass wir Groß- und Kleinschreibung ignorieren. Das ist meistens sinvoll, um Sätze mit bestimmten Tippfehlern trotzdem zu finden.
Als Ergebnis erhalten wir ein kwic-Objekt, dem wir den offensichtlichen und etwas langweiligen Namen kwic zuweisen. In den weiteren Abschnitten werden wir dieses Ergebnis genauer betrachten.
Vertiefung: Komplexere Suchbegriffe
- Mehrere Suchbegriffe als Vektor:
pattern = c("namen", "volkes"). - Mehrwort-Ausdrücke:
pattern = phrase("Im Namen des Volkes"). - Mit
valuetype = globkönnen wir durch das Allzweck-Sternchen (*) Ergänzungen suchen. So wirdpattern = "Volk*"die Begriffe “Volk”, “Volkes” und “Volke” finden. - Mit
valuetype = regexkönnen regular expressions genutzt werden, aber das ist ein Thema für sich.
Namen der Treffer-Dokumente anzeigen Link to heading
Ein kwic-Objekt ist im Grunde nur eine besondere Form eines data.frame. Wir können daher mit den normalen data.frame-Operationen darauf zugreifen.
Um alle Dokumente mit Treffern anzuzeigen wählen wir daher einfach die Variable docname aus und wenden die Funktion unique() darauf an, um jeden Namen nur einmal anzuzeigen.
1unique(kwic$docname)
1## [1] "BVerfG_1998-07-01_S_2_BvR_0441_90_NA_Arbeitspflicht_98_169.txt"
2## [2] "BVerfG_2000-12-14_K_2_BvR_1741_99_NA_Genetischer-Fingerabdruck-1_103_21.txt"
3## [3] "BVerfG_2003-11-05_S_2_BvR_1243_03_NA_Auslieferung-Lockvogel-Völkerrecht-1_109_13.txt"
4## [4] "BVerfG_2003-11-05_S_2_BvR_1506_03_NA_Auslieferung-Lockvogel-Völkerrecht-2_109_38.txt"
5## [5] "BVerfG_2004-02-05_S_2_BvR_2029_01_NA_Langfristige-Sicherheitsverwahrung_109_133.txt"
6## [6] "BVerfG_2004-02-10_S_2_BvR_0834_02_NA_Nachträgliche-Sicherungsverwahrung-1_109_190.txt"
7## [7] "BVerfG_2006-11-08_S_2_BvR_0578_02_NA_Strafrestaussetzung_117_71.txt"
8## [8] "BVerfG_2008-02-26_S_2_BvR_0392_07_NA_Geschwisterinzest_120_224.txt"
9## [9] "BVerfG_2011-05-04_S_2_BvR_2365_09_NA_EGMR-Sicherungsverwahrung_128_326.txt"
10## [10] "BVerfG_2011-06-08_S_2_BvR_2846_09_NA_Nachträgliche-Sicherungsverwahrung-2_129_37.txt"
11## [11] "BVerfG_2012-03-27_S_2_BvR_2258_09_NA_Anrechnung-Massregel-Sicherung-Besserung-Freiheitsstrafe_130_372.txt"
12## [12] "BVerfG_2012-06-20_S_2_BvR_1048_11_NA_Vorbehaltene-Sicherungsverwahrung_131_268.txt"
13## [13] "BVerfG_2013-02-06_S_2_BvR_2122_11_NA_Psychiatrische-Unterbringung-Sicherungsverwahrung_133_40.txt"
14## [14] "BVerfG_2013-07-11_S_2_BvR_2302_11_NA_Therapieunterbringungsgesetz_134_33.txt"
15## [15] "BVerfG_2015-01-14_S_1_BvR_0931_12_NA_Thüringer-Ladenöffnungsgesetz_138_261.txt"
16## [16] "BVerfG_2015-12-15_S_2_BvL_0001_12_NA_Treaty-Override_141_1.txt"
17## [17] "BVerfG_2018-07-24_S_2_BvR_0309_15_NA_Fixierungen_149_293.txt"
18## [18] "BVerfG_2020-12-01_S_2_BvR_0916_11_NA_Elektronische-Aufenthaltsüberwachung_156_63.txt"
Zahl der Treffer anzeigen Link to heading
Wir können uns auch die Anzahl der Treffer anzeigen lassen, d.h. wie oft der Suchbegriff gefunden wurde. Mit nrow() erhalten wir die Zahl der Reihen der KWIC-Tabelle. Diese entspricht der Zahl der Treffer.
1nrow(kwic)
1## [1] 1006
KWIC-Ergebnisse als Tabelle abspeichern Link to heading
Unser eigentliches Interesse gilt bei einem kwic-Objekt aber den einzelnen Treffern und ihrem Kontext. Es enthält für jeden Treffer:
- Den Namen des Dokuments
- Die Position des Treffers
- Den gefundenen Begriff (besonders relevant wenn Wildcards verwendet werden, z.B. bei
pattern = "Verfassung*"würde man erkennen ob “Verfassungsrecht” oder “Verfassungsschutz” gefunden wurde) - Das Kontextfenster vor dem Treffer
- Das Kontextfenster nach dem Treffer
Am sinnvollsten ist es, das gesamte Objekt in eine CSV-Datei auf der Festplatte zu exportieren und diese mit einem handelsüblichen Spreadsheet-Programm wie Excel oder Libre Office zu öffnen und zeilenweise durchzugehen. Beispielsweise so:
1write.csv(data.frame(kwic), file = "kwic.csv", row.names = FALSE)
KWIC-Ergebnisse in R ansehen Link to heading
Da die Anzeige von Tabellen dieser Größe im Web aber etwas schwierig ist lassen wir uns an dieser Stelle nur die ersten fünf Treffer mit head() anzeigen.
1head(kwic, n = 5)
1## Keyword-in-context with 5 matches.
2## [BVerfG_1998-07-01_S_2_BvR_0441_90_NA_Arbeitspflicht_98_169.txt, 1256]
3## [BVerfG_1998-07-01_S_2_BvR_0441_90_NA_Arbeitspflicht_98_169.txt, 7414]
4## [BVerfG_1998-07-01_S_2_BvR_0441_90_NA_Arbeitspflicht_98_169.txt, 7503]
5## [BVerfG_1998-07-01_S_2_BvR_0441_90_NA_Arbeitspflicht_98_169.txt, 7527]
6## [BVerfG_1998-07-01_S_2_BvR_0441_90_NA_Arbeitspflicht_98_169.txt, 7569]
7##
8## . Diese Anweisungen gelten grundsätzlich auch für die | Sicherungsverwahrung |
9## BvR 618/ 92 97 Auch in der | Sicherungsverwahrung |
10## sei dem Beschwerdeführer zuzugeben, daß mit der | Sicherungsverwahrung |
11## , die es rechtfertigten, den Vollzug der | Sicherungsverwahrung |
12## 1 StVollzG gleichwohl materiell auch den Vollzug von | Sicherungsverwahrung |
13##
14## (§ 130 StVollzG ). 1.
15## diene die Arbeitspflicht dem Zweck, nachteiligen Folgen
16## ein anderer Zweck verfolgt werde als mit einer
17## dem Vollzug einer Strafe in bestimmten Belangen anzugleichen
18## prägen dürfe. Jedenfalls sei der Vollzug von
Wir können hier zunächst die relativ langen Dateinamen erkennen, die Informationen über Datum, Aktenzeichen, Namen der Entscheidung und ihre Fundstelle in der BVerfGE angeben. Dieser Dateiname ist gefolgt von einem Komma und der Position des Treffers (idR nur für die maschinelle Weiterverarbeitung relevant). So haben wir aber schon einmal die “Arbeitspflicht”-Entscheidung das BVerfG als relevant erkannt.
In der Mitte (umrahmt von |-Zeichen) sehen wir den Treffer “Sicherungsverwahrung”. Links und rechts davon jeweils das Kontextfenster. Mit dem Kontextfenster können wir folgende Entscheidungen schnell treffen:
- Welche Dokumente sind relevant?
- Enthalten relevante Dokumente viele Treffer?
- Sind die Treffer und ihr Kontext für uns relevant? Falls ja, sollten wir das eigentliche Dokument genauer lesen. Falls nein, können wir so schnell irrelevante Dokumente ausschließen.
- Welche Treffer sind besonders interessant? So können wir in langen Dokumenten schnell zu den wichtigen Stellen vordringen.
Visualisierung: Lexical Dispersion Plot Link to heading
Die Aufbereitung in Tabellenform ist für das genaue Studium der Ergebnisse wichtig. Um einen schnellen Überblick zu erhalten und den Überblick zu behalten, benötigen wir aber eine Visualisierung.
Lexical Dispersion Plots (auch “X-Ray Plot” genannt) sind eine Möglichkeit, um eine KWIC-Analyse schnell und übersichtlich aufzubereiten. Mit {quanteda.textplots}
und textplot_xray() lässt sich das Diagramm aus einem kwic-Objekt leicht generieren.
Der Parameter scale = "relative" bestimmt, dass die Länge der Dokumente auf 1.0 normalisiert werden soll. Die Alternative wäre scale = "absolute". Meistens ist die relative Skala am sinnvollsten.
1textplot_xray(kwic, scale = "relative")
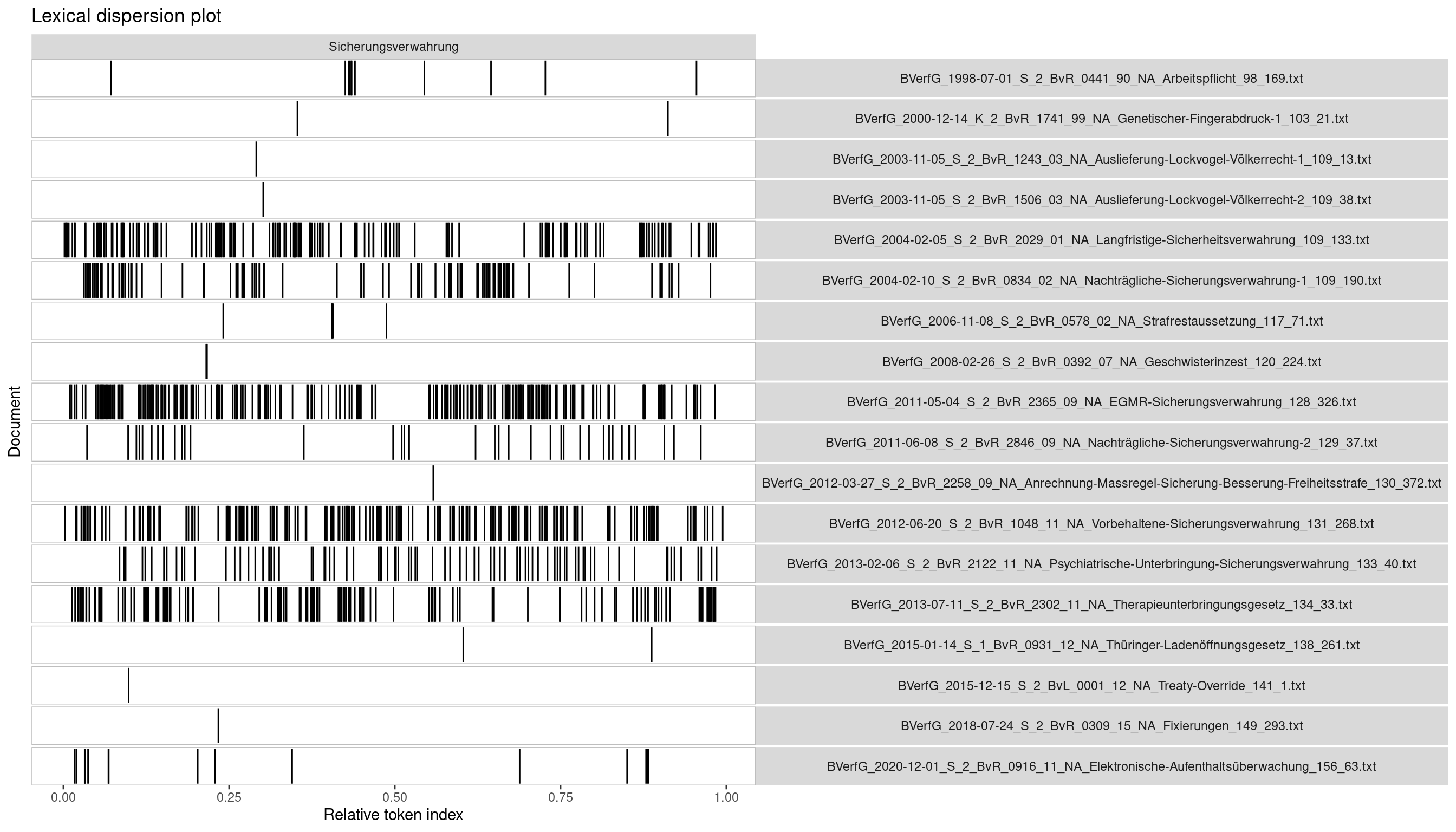
Jede Zeile entspricht einem Dokument (hier: einer Entscheidung des BVerfG). In der rechten Spalte ist jeweils der Dateiname genannt, mit Datum, Aktenzeichen, Name und BVerfGE-Fundstelle. In der linken Spalte zeigen schwarze Striche die Treffer des Suchbegriffs für jede Entscheidung an. Die Länge der Entscheidungen ist auf 1.0 normalisiert, d.h. ein Strich bei 0.5 ist ein Treffer genau in der Mitte der Entscheidung.
Mit Lexical Dispersion Plots können wir schnell folgende Schlüsse ziehen:
- Welche Dokumente haben viele Treffer und sind daher vermutlich wichtig?
- Welche Dokumente haben wenige Trefer und sind daher vermutlich unwichtig?
- Gibt es Abschnitte der Texte, in denen der Begriff besonders häufig auftaucht und die wir uns deshalb ansehen sollten?
Wir erkennen hier sofort, dass die klassischen Entscheidungen des BVerfG zur Sicherungsverwahrung auch eine hohe Trefferquote des Suchbegriffs aufweisen. Selbst wenn wir wenig über das Verfassungsrecht wüssten und die Namen der Entscheidungen nicht kennen, so erlaubt uns diese rein maschinelle Analyse trotzdem sehr schnell die zentrale Rechtsprechung des BVerfG zur Sicherungsverwahrung zu identifizieren. Als Praktiker:innen können wir sofort anfangen damit zu arbeiten.
Zudem haben wir einige Entscheidungen mit wenigen Treffern gefunden. Bei einer wissenschaftlichen Fragestellung können wir uns nun Gedanken machen, ob diese nicht-zentralen Entscheidungen wichtige Entwicklungen der Rechtsprechung schon früher angedeutet haben, später nur anwenden oder zusätzlichen Kontext liefern. In jedem Fall sind ihre Textstellen schnell ausgewertet.
Zusammenfassung Link to heading
In dieser Einheit haben wir uns die Key Word in Context (KWIC) Methode angesehen und auf einen Datensatz mit Entscheidungen der amtlichen Sammlung des Bundesverfassungsgerichts (BVerfGE) angewendet. Dabei haben wir die relevanten Dokumente und Trefferzahlen für den Begriff “Sicherungsverwahrung” bestimmt, die relevanten Textstellen extrahiert und uns mit einem Lexical Dispersion Plot einen Überblick verschafft.
Mit einer KWIC-Analyse lassen sich also:
- Relevante Dokumente schnell finden
- Relevante Textstellen schnell finden
- Eine Textsammlung vollständig auswerten
- Ein Überblick für ein nicht-technisches Publikum erstellen (z.B. zur Besprechung mit Mandantinnen)
Viel Erfolg bei der Anwendung!
Vertiefung: Corona-Entscheidungen des BVerfG
Mit der KWIC-Methode bestimme ich regelmäßig die Corona-Entscheidungen des BVerfG und sortiere sie in einen separaten Datensatz. In diesem Fall sind es die Suchbegriffe “Corona”, “SARS-CoV” und “COVID”. Der Datensatz ist hier verfügbar:
Fobbe, S. (2023). Corona-Rechtsprechung des Bundesverfassungsgerichts (BVerfG-Corona) (2023-02-26) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.7807020
Informationen zur strengen Replikation Link to heading
Dieses Tutorial wurde zuletzt aktualisert am: 2026-02-08.
1sessionInfo()
1## R version 4.2.2 Patched (2022-11-10 r83330)
2## Platform: x86_64-pc-linux-gnu (64-bit)
3## Running under: Debian GNU/Linux 12 (bookworm)
4##
5## Matrix products: default
6## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
7## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.21.so
8##
9## locale:
10## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
11## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
12## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
13## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
14## [9] LC_ADDRESS=C LC_TELEPHONE=C
15## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
16##
17## attached base packages:
18## [1] stats graphics grDevices datasets utils methods base
19##
20## other attached packages:
21## [1] quanteda.textplots_0.95 quanteda_4.1.0 zip_2.3.1
22##
23## loaded via a namespace (and not attached):
24## [1] Rcpp_1.0.13 highr_0.11 pillar_1.9.0 bslib_0.8.0
25## [5] compiler_4.2.2 jquerylib_0.1.4 tools_4.2.2 stopwords_2.3
26## [9] digest_0.6.37 tibble_3.2.1 jsonlite_1.8.8 evaluate_0.24.0
27## [13] lifecycle_1.0.4 gtable_0.3.5 lattice_0.20-45 pkgconfig_2.0.3
28## [17] rlang_1.1.4 Matrix_1.5-3 fastmatch_1.1-4 cli_3.6.3
29## [21] yaml_2.3.10 blogdown_1.19 xfun_0.47 fastmap_1.2.0
30## [25] withr_3.0.1 dplyr_1.1.4 knitr_1.48 generics_0.1.3
31## [29] vctrs_0.6.5 sass_0.4.9 tidyselect_1.2.1 grid_4.2.2
32## [33] glue_1.7.0 R6_2.5.1 fansi_1.0.6 rmarkdown_2.28
33## [37] bookdown_0.40 farver_2.1.2 ggplot2_3.5.1 magrittr_2.0.3
34## [41] scales_1.3.0 htmltools_0.5.8.1 colorspace_2.1-1 renv_1.0.7
35## [45] labeling_0.4.3 utf8_1.2.4 stringi_1.8.4 munsell_0.5.1
36## [49] cachem_1.1.0